Every tech leader knows the fairy tale: “Great at code = great at people.” We spot a developer whose pull-requests sparkle, whose architectural sketches belong in the Museum of Modern Art (MoMA), and we conclude: Surely the next logical step is management. Hand them a team, a budget sheet, and calendar invites labeled one-on-one—problem solved, succession assured, meritocracy intact.
Why do we cling to that script?
It feels efficient. One promotion fills a leadership gap and “rewards” performance in a single stroke.
It flatters our worldview. If craft excellence naturally matures into leadership excellence, we can skip the messy bits—behavioral coaching, emotional labor, process literacy.
It defers the real work. Designing dual career paths, running mentorship programs, and funding effective leadership curricula requires time and resources. A title change? Five minutes in the HR system.
The story is seductive precisely because it postpones accountability. We tell ourselves we’re empowering talent while really outsourcing leadership development to hope and good intentions.
The Uncomfortable Truth (and Why It Hurts)
Promoting the wrong way doesn’t multiply talent—it divides it. Here’s how the math actually plays out:
Lost Throughput Your top coder’s flow time evaporates under meeting overload. Velocity graphs flatten, incident queues grow, and suddenly the only one who understood the core module’s dark corners is too busy running sprint ceremonies to refactor them.
Half-Formed Leadership Technical mastery provides exactly zero reps in conflict mediation, coaching awkward juniors, translating KPIs into meaning, or defending budgets to product marketing. Lacking those muscles, the new lead leans on what they know: code metrics. The team notices—and disengages.
Silent Turnover The “reward” quickly feels like a swap: deep work for calendar chaos, elegant abstractions for emotional entropy. The promoted developer updates LinkedIn, while the remaining developers wonder whose head is next on the altar.
Quality Debt Marginal leadership is evident in customer-visible defects, including unclear priorities, rushed fixes, brittle releases, and talent churn that erodes domain context. Quality managers (hi, that’s me) see the defects long before finance sees the costs.
Put bluntly: you traded an A-level technician for a C-level manager and a demoralized team—all because the promotion path was smoother than the preparation path.
“But Some Devs Do Become Great Leaders!”
Absolutely. The problem isn’t the who; it’s the how. Leadership success isn’t a genetic twist unlocked by a title. It’s desire, training, feedback loops, and systemic support. Remove any of those, and even the most people-centric engineer will flounder.
Promotion Without Perdition: A Better Deal for Everyone
The fix is neither exotic nor expensive—it just requires intent. Here are five moves that prevent the sacrificial ceremony:
Ask, Don’t Assume Before sending the promotion email, run a candid discovery: Do you actually want to lead? Leadership is a career change, not a pay bump. Some devs will say “not now,” and that’s a productivity victory, not a setback.
Create Dual Career Tracks Staff-Plus, Principal Engineer, Distinguished Architect—whatever you call it, a parallel path allows technical excellence to continue compounding, delivering the highest ROI.
Treat Promotion Like Product Launch Run a beta: limited team scope, clear success criteria, access to a mentor. Release notes after 90 days, iterate, and then roll out to a broader audience. You wouldn’t deploy untested code to prod; why do it with leadership?
Install Leadership Enablement, Not Just Learning & Development (L&D) Training is content; enablement is context. Pair formal instruction (coaching conversations, budgeting, conflict skills) with on-the-job shadowing and real-time feedback. Quality Management embeds these ladders into every transformation program—because upskilling managers is cheaper than rehiring engineers.
Instrument the Human Metrics If you graph latency, you can graph psychological safety. Quarterly pulse surveys, turnover-risk heat-maps, mentorship-hours tracked—make the invisible visible and you’ll correct course before farewell cakes are ordered.
What Changes for the Business?
Velocity rebounds as experts stay in their flow state or acquire leadership skills without abandoning their craft.
Quality indicators improve—fewer production regressions, less rework, more predictable releases.
Engagement scores climb because employees see career growth that respects their strengths.
Retention stabilizes, cutting backfill costs and preserving domain knowledge.
The QM Layer
Quality Management embeds talent enablement alongside architecture, quality, and innovation, ensuring leadership growth never occurs in a vacuum. Whether you need a one-off upskilling sprint, a dual-track career lattice, or a fractional leadership coach, the goal is the same: elevate people without exiling them from their genius.
The Lip Service Problem: When “Support” Means Silence
We’ve all been there. Leadership stands up in an all-hands and says, “Quality is our top priority.” There’s a nod. Maybe even a round of applause. And then… nothing.
No changes to resourcing. No new metrics. No shift in incentives. And absolutely no change in behavior.
This is what I call the lip service death spiral:
Step 1: Execs declare quality important.
Step 2: Teams wait for signals to change how they work.
Step 3: Nothing happens.
Step 4: Teams go back to optimizing for delivery speed.
Step 5: Quality quietly dies.
Here’s the uncomfortable truth: most leadership teams think endorsing quality is enough. But saying “quality matters” without embodying, enabling, or enforcing it is like shouting “defense!” from the sidelines while your team gets steamrolled.
If quality starts at the top, then so does the rot.
Metrics, Models, and Misalignment: Why Good Intentions Fail
Let’s be honest. Quality isn’t mysterious. It just requires attention, accountability, and investment. Yet most organizations suffer from one or more of these blind spots:
No measurable definition of quality. Ask ten leaders what “quality” means, get ten different answers.
No one owns it. Engineering thinks it’s product’s job. Product thinks it’s QA. QA thinks it’s a lost cause.
No feedback loop. Post-mortems happen. But nothing changes.
Want to know how seriously a company takes quality?
Don’t look at the mission statement. Look at the backlog.
Are bug fixes prioritized?
Are teams measured on incident reduction?
Does anyone track the cost of rework?
If quality isn’t resourced, tracked, and rewarded — it won’t happen. It’s not sabotage. It’s entropy. In fast-moving environments, quality atrophies unless it’s deliberately sustained.
And when leadership fails to model what “good” looks like, they accidentally normalize the bad.
How to Stop Killing Quality: Start Leading It
Want to fix this? You can. But it starts by getting brutally honest:
Ask: Do we really value quality? Or do we just say we do? If you’re not investing in it, you’re not valuing it.
Set clear, shared definitions of quality. Across product, engineering, QA, and leadership. No wiggle room.
Track quality like you track delivery. DORA metrics, escaped defect rates, rework cost — pick something. Just make it visible.
Reward teams for preventing problems, not just shipping features. The team that reduces support tickets by 40% deserves just as much love as the one who ships that flashy new feature.
Lead by example. If you’re in leadership, stop tolerating crap quality because “the deadline is tight.”
Here’s the kicker: you don’t need to hire more QA. You need to hire more accountability.
It was supposed to be a routine rollout. Nothing fancy. Just another step in a multi-phase digital transformation. The project team was confident. “We’ve done this before,” they said. “It should be fine.”
Only this time, it wasn’t. Because this time, they were flying blind with their eyes wide open.
Parallel launches across regions. Overlapping system updates. A handful of key engineers tied up in a second initiative. A predictive analytics model had already flagged this constellation as high risk. The warning dashboard flashed red.
But the team? They felt good.
Gut feeling said: smooth sailing. Data said: brace for impact.
Guess who was right?
Two hours into the rollout, user support channels lit up. Latency in the EU region. Inconsistent behavior in the APAC login system. And a classic domino effect: one delayed sync cascaded into three customer-facing outages.
Was this unforeseeable? Not even close. It was practically scripted. The early warning dashboard had simulated this failure path weeks in advance. But because it was “just a model” and “we’ve always managed before,” the data was ignored.
The dangerous illusion of experience
In software delivery, a special kind of overconfidence arises from success. When you’ve survived ten chaotic launches, you start believing you’re invincible. The gut starts feeling smarter than the numbers.
But let’s be blunt: your gut is not a risk management tool. It’s a storytelling machine, not a sensor. It remembers the wins and conveniently forgets the close calls.
Data, on the other hand, has no ego. It doesn’t care how many late-night war rooms you survived. It just tells you what’s likely to happen next, based on patterns you’d rather not relive.
And yet, in critical moments, many teams still fall back on hope. Or worse: consensus-driven optimism. “No one sees an issue, so we should be good.” That’s not alignment. That’s groupthink with a smile.
From feelings to foresight: build your risk radar
So, how do you stop your team from betting the farm on good vibes?
Simple: give them a better radar. And make it visible.
Enter the risk heat map and early-warning dashboard. These tools aren’t just fancy charts for the PMO. They’re operational x-ray glasses:
Risk heat maps visualize where complexity and fragility intersect. You see hotspots, not just in systems, but in dependencies, staffing, and timing.
Early-warning dashboards highlight leading indicators: skipped tests, overbooked engineers, unacknowledged alerts, and delayed decision-making. All the invisible signals your gut can’t process.
And here’s the kicker: when these tools are part of your regular rituals—planning, retros, leadership syncs—they stop being side notes. They become part of how you think.
Because when risk becomes visible, it becomes manageable. And when it’s manageable, it’s not scary.
So go ahead, listen to your gut. But if your dashboard is screaming, maybe it’s time to stop hoping and start acting.
Quality is not just what you build. It’s how you prepare.
A few months ago, a product team proudly told us they had reached “CI/CD nirvana.” They were pushing updates to production multiple times a day—zero friction, total speed.
Until they broke production.
It wasn’t just a glitch. One bad release triggered cascading failures in dependent services. It took them three full days to stabilize the system, get customer support under control, and recover user trust. Exhausted and embarrassed, the team quietly rolled back to a safer cadence.
This isn’t unusual. Teams chasing speed often treat quality gates as enemies of velocity. They see checks like code coverage thresholds, linting rules, or pre-deployment validations as bureaucratic drag.
But here’s the truth:
Speed without safety is just gambling.
If your process lets anything through, then every deployment is a roll of the dice. You might ship fast for a week, a month, maybe more. But the day you land on snake eyes, you’ll pay for every shortcut you took.
What We Learned (the Hard Way)
After that incident, the team didn’t give up on speed. They just got smarter about protecting it.
They implemented a lightweight set of automated quality gates:
Code coverage minimums in the CI pipeline
Linting enforcement to catch common errors
Pre-deployment integration tests for critical flows
Canary releases with health monitoring
They didn’t add red tape. They added resilience.
The result? Rollback incidents dropped by 70%. Developers kept shipping daily, but now with a net under the high wire.
Velocity didn’t slow down. Fear did.
The Tool: Quality Gates in CI/CD
If you want sustainable speed, you need confidence. And confidence comes from knowing that what you ship won’t explode at runtime.
That’s what quality gates are for:
Linting: Enforce basic hygiene before code gets merged.
Test coverage thresholds: Ensure your tests aren’t just an afterthought.
Static analysis: Catch complexity, potential bugs, and anti-patterns early.
Integration test suites: Prove the whole system still works.
Deployment safety checks: Validate infra before rolling out.
These aren’t blockers. They’re bodyguards for your speed.
Yes, they take time to set up. Yes, they sometimes delay a bad commit from shipping.
But that’s the point.
A quality gate that blocks a bug before it hits production just bought you hours (or days) of recovery time you never had to spend.
Final Thought
Skipping quality gates to ship faster is like removing your car’s brakes to save weight.
Sure, you might hit top speed quicker — until the first sharp turn.
Velocity isn’t about how fast you can go. It’s about how fast you can go safely.
Build that into your pipelines, and speed becomes sustainable. Ignore it, and you’re not scaling — you’re setting a timer on your next incident.
A team of developers once skipped a round of tests to hit a feature deadline.
When asked why they cut corners, they didn’t mumble excuses. They simply said, “We thought speed was more important.”
That belief didn’t come from the backlog. It didn’t come from JIRA.
It came from leadership.
Not because leadership said, “Skip the tests.” But because leadership didn’t say anything at all.
Silence is a signal. And in high-pressure environments, silence is interpreted as permission.
This is how culture works: it quietly instructs behavior when no one’s looking.
You can write all the processes you want, print all the test coverage charts, and run audits until your dev teams go cross-eyed. But when a release is at risk and time is tight, your team will choose whatever they believe leadership values most.
And if quality isn’t one of those values?
It gets eaten alive.
We see this over and over in scaling tech companies:
High-performing teams start cutting corners to keep pace.
Test coverage drops.
Incidents spike.
Devs burn out.
Leadership reacts with more process. More rules. More compliance steps.
But process without belief is just theater.
You can’t audit your way out of a cultural issue. Because quality is a leadership behavior, not just an engineering task.
If you want quality to survive under pressure, you have to intentionally shape the culture.
How?
By creating feedback loops. By making quality visible. By rewarding it in moments that matter.
Here’s one deceptively simple tool:
Once a month, ask your teams: What quality behaviors did you see being rewarded? What behaviors got ignored — or even punished?
That’s it.
No fancy dashboards. No 30-slide decks. Just direct, human truth about what your culture is actually teaching.
Then act on it.
Call out the moments where quality showed up — even when it slowed things down. Tell the stories. Share them publicly. Make it known that quality isn’t a luxury, it’s a leadership principle.
Because if you don’t define the culture, the deadline will.
And that deadline doesn’t care about your test coverage.
A few years ago, I worked with a growing software company that struggled to deliver features on time. Deadlines were slipping, and teams were frustrated.
When I asked developers what was causing the delays, they pointed to endless bug fixes that took precedence over new features.
One senior developer told me, “We know where the bugs come from, but it’s impossible to stop them—tight timelines don’t allow us to focus on quality up front.”
This reminded me of Shigeo Shingo’s timeless wisdom:
“It’s the easiest thing in the world to argue logically that something is impossible. Much more difficult is to ask how something might be accomplished.”
Everyone can come up with a thousand reasons why something won’t work. But the question we should ask instead would be: “What needs to happen to make it work?”
Shingo’s principles are as relevant to software development as they are to manufacturing. Instead of accepting problems as inevitable, he challenged teams to rethink their processes and eliminate issues at the source.
Applying this mindset to the software team, we implemented automated testing and continuous integration (CI).
While it required initial effort, these changes reduced bugs significantly by catching issues earlier in development.
Teams were empowered to focus on building new features, and morale improved as they delivered higher-quality software on time.
Ask “How Might We?”: When faced with recurring issues, ask your team to brainstorm ways to solve them permanently, even if the solution initially seems challenging.
Adopt Automation: Automate tasks prone to human error, like testing or code reviews, to catch defects early and streamline workflows.
Build Quality into the Process: Use practices like pair programming, code linting, or CI/CD pipelines to ensure problems are addressed as they arise, not after release.
The takeaway? Stop accepting “impossible” as the answer.
With the right mindset and tools, you can transform recurring issues into opportunities for innovation.
Have you ever turned an “impossible” challenge into a win? If so, share your story with me—I’d love to hear it!
Early in my career as a quality manager, I was part of a team tasked with overhauling a software company’s quality assurance processes. We crafted a robust strategy, implemented cutting-edge systems, and restructured departments for optimal efficiency.
On paper, everything was flawless. Yet, months later, quality issues persisted. Curious about the disconnect, I walked the floor, asked questions, talked to people, listened, and noticed that employees were still clinging to their old methods and were resistant to the new processes we introduced.
This experience taught me a crucial lesson: even the best strategies and systems fail if they don’t consider the human element.
As John Kotter wisely said, “The central issue is never strategy, structure, culture, or systems. The core of the matter is always about changing people’s behavior.”
Real transformation happens when we focus on helping individuals understand, embrace, and commit to new ways of working.
This reminds us that at the heart of every organizational change are people whose behaviors determine success or failure.
Hence, please don’t underestimate the power of change management – or the danger of not considering it.
Many companies consider software outsourcing a strategic decision to leverage specialized skills, reduce costs, or improve efficiency. However, outsourcing can fail to meet its objectives without a structured approach. Drawing from extensive experience as a Quality Manager, here is a robust four-phase process to ensure outsourcing success.
Most companies neglect the first 2 phases, struggle then in phase 3, and the project fails heroically in phase 4. Hence, consider putting some effort into the first two phases to have smoother phases 3 and 4 and, most importantly, a successful outsourcing project closure.
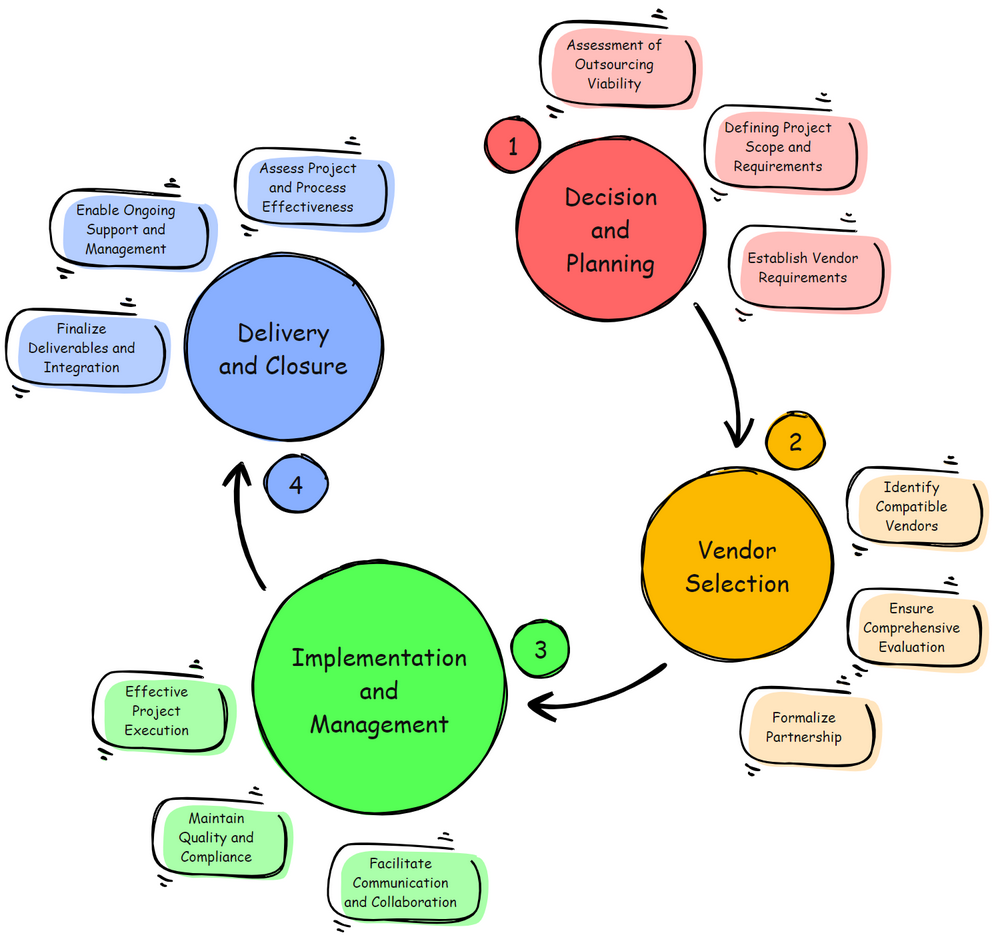
Phase 1: Decision and Planning
The initial phase focuses on evaluating whether outsourcing is suitable for your project at all. This involves an in-depth assessment of the business needs and potential benefits versus the risks. Companies must also define the project’s scope and requirements clearly. This clarity ensures potential vendors understand what is expected of them, reducing miscommunications and project scope creep.
Key actions include:
Assess outsourcing viability by examining the alignment with business goals and the cost-effectiveness of outsourcing versus in-house development.
Define project scope and requirements to specify project objectives, deliverables, technical needs, and success metrics.
Establish vendor requirements to ensure potential partners have technical expertise, compliance standards, and communication capabilities.
Phase 2: Vendor Selection
Choosing the right vendor is critical. This phase involves identifying vendors with technical capabilities that align with your company’s business ethics and cultural values.
Steps to ensure effective vendor selection:
Identify compatible vendors through rigorous evaluation of their technical and cultural alignment with your project needs.
Ensure a comprehensive evaluation by using detailed Requests for Proposals (RFPs) and structured interviews to assess potential vendors’ capabilities and proposals.
Formalize partnership by negotiating and signing contracts clearly defining roles, responsibilities, scope, and expectations.
Phase 3: Implementation and Management
With the vendor selected, the focus shifts to project execution. Effective management ensures the project remains on track and meets all defined objectives.
Critical management tasks include:
Effective project execution to oversee the project from start to finish, ensuring adherence to the project plan and achievement of milestones.
Maintain quality and compliance through regular quality checks and adherence to industry standards.
Facilitate communication and collaboration to ensure all stakeholders are aligned, which helps address issues promptly and adjust project scopes as needed.
Phase 4: Delivery and Closure
The final phase involves integrating and closing out the project. Ensuring that the deliverables meet quality standards and are well integrated into existing systems is paramount.
Key closure activities:
Finalize deliverables and integration to ensure all software meets quality standards and integrates smoothly with existing systems.
Enable ongoing support and management by training internal teams to manage and maintain the software effectively.
Assess project and process effectiveness through a post-implementation review to identify successes, lessons learned, and areas for improvement.
Conclusion
Effective outsourcing is not just about choosing a vendor and signing a contract; it’s a comprehensive process that requires careful planning, execution, management, and closure. By adhering to these four structured phases, companies can enhance their chances of outsourcing success, leading to sustainable benefits and growth. This approach not only helps in achieving the desired outcomes but also in building strong, productive relationships with outsourcing partners.
A Business Impact Analysis (BIA) is a systematic process that organizations undertake as part of their Business Continuity Planning (BCP) and Business Continuity Management (BCM) efforts. It is a crucial phase that lays the foundation for developing robust and effective strategies to mitigate the impacts of potential disruptions on critical business operations.
Clarity on the objectives of a BIA is essential for ensuring a comprehensive and focused analysis. Organizations can gather valuable insights and make informed decisions to safeguard their operations and maintain business continuity by aligning the process with well-defined objectives.
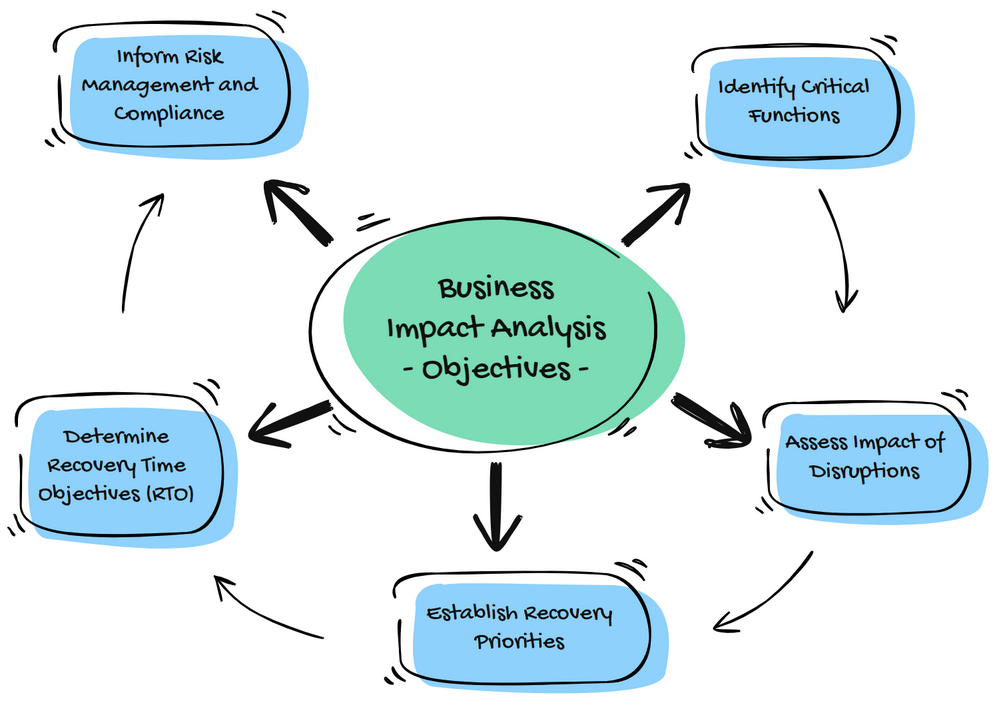
Here are some key objectives that should guide the BIA process:
Identify Critical Functions: The primary objective of a BIA is to identify the critical functions and processes that are vital to the organization’s survival and continued operation. The organization can prioritize recovery efforts during disruptions by pinpointing these essential functions and ensuring that resources are allocated effectively.
Assess Impact of Disruptions: A BIA aims to quantify potential disruptions’ operational and financial impacts on the identified critical functions. This assessment helps organizations understand the risks associated with business continuity and the possible consequences of inadequate recovery strategies.
Establish Recovery Priorities: The BIA enables organizations to prioritize recovery efforts based on criticality and impact assessments. Organizations can allocate resources efficiently during a crisis by understanding which functions require immediate attention and which can be addressed later, minimizing downtime and potential losses.
Determine Recovery Time Objectives (RTO): The BIA process helps define acceptable downtime or Recovery Time Objectives (RTO) for each critical function. These RTOs guide the development of recovery plans and inform the investments required to achieve the desired level of resilience.
Inform Risk Management and Compliance: The insights gained from the BIA feed into the broader risk management process and compliance requirements. By providing detailed information on potential vulnerabilities and regulatory obligations, the BIA supports organizations in developing comprehensive risk mitigation strategies and ensuring compliance with relevant industry standards and regulations.
A well-executed BIA ensures that organizations can respond promptly and effectively to disruptions, maintaining operational integrity and stakeholder confidence by clearly defining and aligning with these objectives. It serves as a critical foundation for building resilience and minimizing the impact of unforeseen events on business continuity.
Embarking on the Journey: The Critical Role of DoD in Agile Projects
With its rapid developments and impressive results, Navigating the world of Agile demands one essential element for success: clear definitions. That’s where the Definition of Done (DoD) comes into play.
Imagine a scenario: a team is tasked with building a car. The specifications are clear, but what does ‘done’ really mean?
For the engineer, ‘done’ might mean the engine runs smoothly. For the designer, it’s about the final polish and aesthetics. For the quality inspector, ‘done’ is not reached until every safety test is passed with flying colors.
Here lies the essence of the DoD dilemma – without a universally accepted definition of ‘done,’ the car might leave the production line with a roaring engine and a stunning design but lacking critical safety features.
In Agile projects, this is a common pitfall. Teams often have varied interpretations of completion, leading to inconsistent and sometimes incomplete results.
A meticulously constructed DoD serves as the critical point of convergence for different team viewpoints, guaranteeing that a task is only considered ‘done’ when it fully satisfies every requirement – encompassing its functionality and aesthetic appeal, safety standards, and overall quality.
Let’s explore how the DoD transforms Agile projects from a collection of individual efforts into a cohesive, high-quality masterpiece.
From Chaos to Clarity: A Real-World Story of Transformation
Let me take you back to a time in my career that perfectly encapsulates the chaos resulting from a lack of a universally understood DoD. In a former company, our project landscape resembled a bustling bazaar – vibrant but chaotic.
Both internal and external teams were diligently working on a complex product, each with their own understanding of ‘completion.’
The first sign of trouble was subtle – code contributions from different teams that didn’t fit together smoothly. A feature ‘completed’ by one team would often break the functionality of another. The build failures became frequent, and the debugging sessions became prolonged detective hunts, frequently ending in finger-pointing.
I recall one incident vividly. A feature was marked ‘done’ and passed on for integration. It looked polished on the surface – the code was clean and functioned as intended. However, during integration testing, it failed spectacularly.
The reason? It wasn’t compatible with the existing system architecture. The team that developed it had a different interpretation of ‘done.’ For them, ‘done’ meant working in isolation, not as a part of the larger system. Hence, we had to rework everything, throwing away weeks of work.
This experience was our wake-up call. It made us realize that without a shared, clear, and comprehensive DoD, we were essentially rowing in different directions, hoping to reach the same destination. It wasn’t just about completing tasks but about integrating them into a cohesive, functioning whole.
This realization was the first step towards our transformation – from chaos to clarity.
Unveiling the DoD: Components of a Robust Agile Framework
After witnessing firsthand the chaos that ensues without a clear DoD, let’s unpack what a robust Definition of Done should encompass in an Agile project.
But let’s start with a definition.
What is a Definition of Done (DoD)?
The Definition of Done (DoD) is an agreed-upon set of criteria in Agile and software development that specifies what it means for a task, user story, or project feature to be considered complete.
The development team and other relevant stakeholders, such as product owners and quality assurance professionals, collaboratively establish this definition.
The DoD typically encompasses various deliverable aspects, including coding, testing (unit, integration, system, and user acceptance tests), documentation, and adherence to coding standards and best practices.
By clearly defining what “done” means, the DoD provides a clear benchmark for completion, ensuring that everyone involved in the development process has a shared understanding of what is expected for a deliverable to be considered finished.
Now we know what a DoD is. But I’d like to elaborate once more on why it is needed:
Why is the Definition of Done Necessary?
The DoD is essential for several reasons.
Firstly, it ensures consistency and quality across the product development lifecycle. By having a standardized set of criteria, the development team can uniformly assess the completion of tasks, thus maintaining a high-quality standard across the project.
Secondly, it facilitates better collaboration and communication between the teams and with stakeholders. When everyone agrees on what “done” means, it reduces ambiguities and misunderstandings, leading to more efficient and effective collaboration.
Thirdly, the DoD helps in effective project tracking and management. It provides a clear framework for assessing progress and identifying any gaps or areas needing additional attention.
Finally, it contributes to customer satisfaction; a well-defined DoD ensures that the final product meets the client’s expectations and requirements, as every aspect of the product development has been rigorously checked and validated against the agreed-upon criteria.
Right, but what does such a DoD look like?
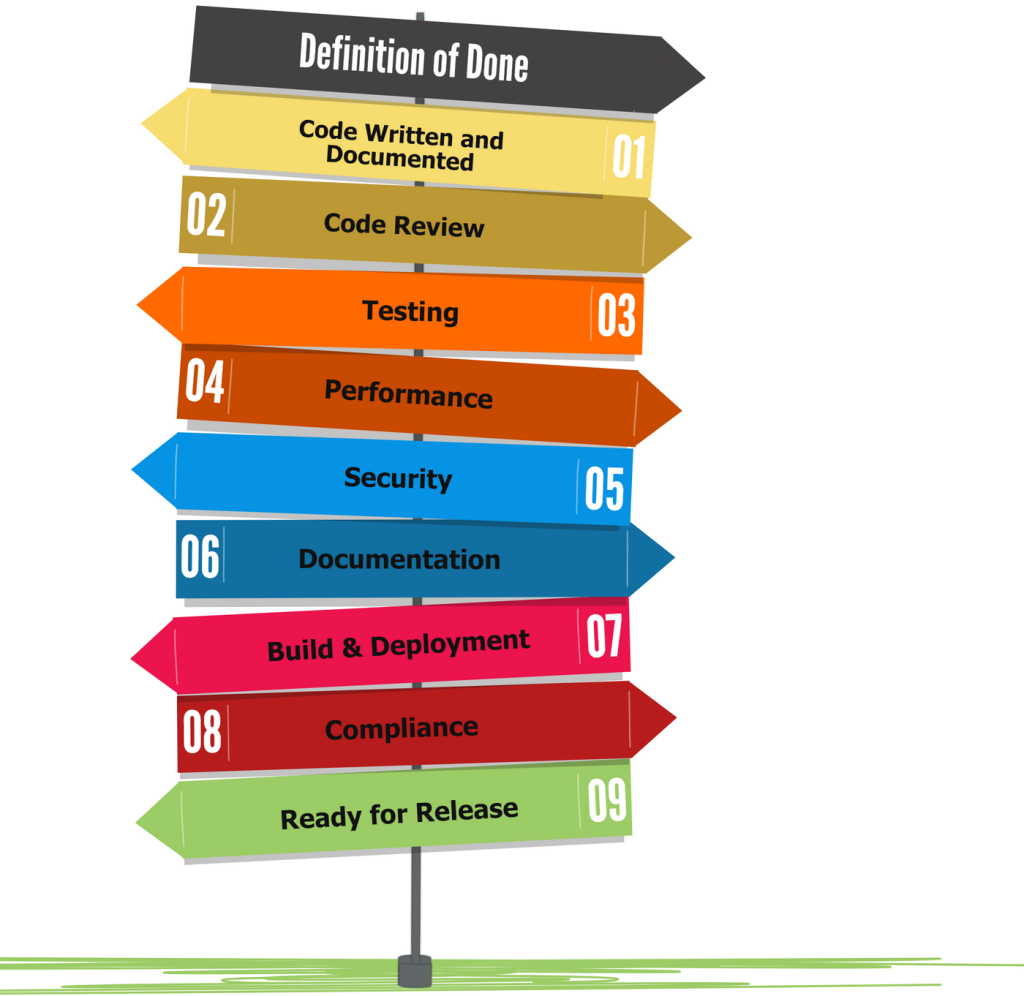
Understanding the key components of a Definition of Done (DoD) is crucial for a successful Agile project. Here are some typical elements that can be included in a DoD. Remember, these are illustrative; depending on your team’s consensus and project requirements, your DoD may have more, fewer, or different points.
Code Written and Documented: Not only should the code be fully written and functional, but it should also be well-documented for future reference. For instance, a user story isn’t done until the code comments and API documentation are completed.
Code Review: The code should undergo a thorough review by peers to ensure quality and adherence to standards. A user story can not be marked done when it has not been reviewed and approved by at least two other team members.
Testing: This includes various levels of testing – unit, integration, system, and user acceptance tests. A feature is done when all associated tests are written and passed successfully, ensuring the functionality works as expected.
Performance: The feature must meet performance benchmarks. This means that it functions correctly and does so within the desired performance parameters, like load times or response times.
Security: Security testing is critical. A feature can be considered done when it has passed all security audits and vulnerability assessments, ensuring the code is secure from potential threats.
Documentation: Apart from code documentation, this includes user and technical documentation. A task is complete when all necessary documentation is clear, comprehensive, and uploaded to the relevant repository.
Build and Deployment: The feature should successfully integrate into the existing build and be deployed without issues. For instance, a feature is done when it’s deployed to a staging environment and passes all integration checks.
Compliance: Ensuring the feature meets all relevant regulatory and compliance requirements. For example, a data processing feature might only be considered done after verifying GDPR compliance.
Ready for Release: Lastly, the feature is not truly done until it’s in a releasable state. This means it’s fully integrated, tested, documented, and can be deployed to production without any further work.
The last point is probably the most important since it indirectly includes all other points. The feature should be “potentially releasable”. This means it would be ready to be released at any time. And this, of course, can only be answered with yes if the points before are considered.
While these are common elements in many DoDs, it’s important for teams, especially in projects with multiple teams or external stakeholders, to agree on these points to ensure consistency and quality across the board. A well-defined DoD is a living document, subject to refinement and evolution as the project progresses and as teams learn and adapt.
Your Roadmap to Agile Excellence: Implementing DoD Effectively
Having understood the pivotal role of DoD and its components, the next step is its effective implementation. This is where theory meets practice and where true Agile excellence begins. Let’s explore the roadmap to integrate DoD into your Agile projects effectively.
Collaborative Creation: The DoD should be a collaborative effort, not a top-down mandate. Involve all relevant stakeholders – developers, QA professionals, product owners, and, if possible, even customers. This collaborative approach ensures buy-in and shared understanding across the team.
Customization is Key: There is no one-size-fits-all DoD. Each project is unique, and your DoD should reflect that. Consider your project’s specific needs and goals when defining your DoD criteria.
Keep it Clear and Concise: A DoD overloaded with too many criteria can be as ineffective as having none. Keep your DoD clear, concise, and focused on what truly matters for the project’s success.
Regular Reviews and Updates: Agile is all about adaptability. Regularly review and update your DoD to reflect changes in project scope, technology advancements, or team dynamics. This ensures that your DoD remains relevant and effective throughout the project lifecycle.
Visibility and Accessibility: Ensure the DoD is visible and accessible to all team members. Whether on a physical board in the office or a digital tool accessible remotely, having the DoD in plain sight keeps everyone aligned and focused.
Conclusion: Implementing a clear and comprehensive DoD is a game-changer in Agile project management. It transforms ambiguity into clarity, aligns team efforts, and significantly enhances the quality of the final deliverable. If you want to elevate your Agile projects, start by refining your DoD.
And remember, if you need more personalized guidance or assistance in creating an effective DoD for your team, I’m here to help. Let’s connect and turn your Agile projects into success stories.
In business and organizational management, a policy is a guiding principle or protocol designed to guide decisions and actions toward a specific goal. Policies are formalized rules or guidelines that an organization adopts to ensure consistency, compliance, and efficiency in its operations. They serve as a roadmap for management and employees, outlining expected behaviors and procedures and providing a framework for decision-making and daily activities.
What is a Quality Policy?
A quality policy is a subset of these organizational policies focused on the quality aspect of a company’s operations and outputs. It’s a statement or document that clearly defines a company’s commitment to quality in its products or services. The quality policy is the cornerstone of a company’s quality management system, setting the tone and direction for all quality-related activities.
Why is a Quality Policy Needed?
The necessity of a quality policy arises from its role in establishing a uniform understanding of quality within the organization. It acts as a central reference point for all employees, from leadership to frontline staff, ensuring everyone works towards the same quality objectives. This policy helps in:
Aligning with Customer Expectations: Setting quality benchmarks ensures that the products or services meet or exceed customer expectations, thus enhancing customer satisfaction and loyalty.
Regulatory Compliance: Many industries have regulatory requirements regarding quality. A quality policy helps adhere to these standards, avoid legal issues, and maintain a good reputation.
Consistency in Quality: It ensures consistency in the quality of products or services, irrespective of the scale of operations or the company’s geographical spread.
Continuous Improvement: A well-crafted quality policy promotes a culture of continuous improvement, driving innovation and keeping the company competitive.
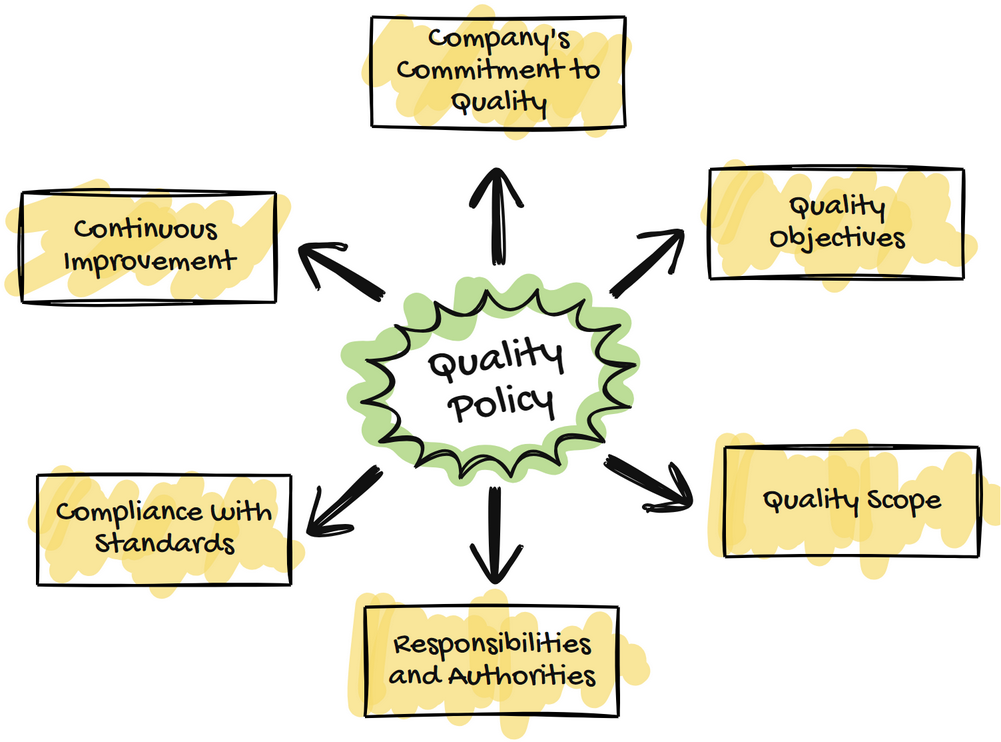
Main Points in a Quality Policy
A typical quality policy will cover the following key areas:
Company’s Commitment to Quality: It starts with a statement of commitment from the top management, underscoring its commitment to maintaining high quality in its offerings.
Quality Objectives: These are specific, measurable goals the company aims to achieve in quality. They might include targets like reducing defect rates, improving customer satisfaction scores, or ensuring timely delivery.
Scope of the Policy: This part defines who is covered by the policy, usually including all employees and departments within the organization.
Responsibilities and Authorities: It clarifies the roles and responsibilities of different team members in upholding the quality standards, ensuring everyone knows their part in the quality management system.
Compliance with Standards: The policy often references industry standards or regulatory requirements that the company commits to comply with.
Continuous Review and Improvement: A statement on how the policy will be reviewed and updated to adapt to changing business environments or customer needs.
In conclusion, a quality policy is a vital component of an organization’s overall strategy, embedding a commitment to excellence in every aspect of its operations. It’s not just a set of rules; it reflects the company’s ethos and a blueprint for sustainable success. By prioritizing quality, organizations can ensure long-term customer satisfaction and continuous growth in an ever-evolving business landscape.
Embarking on the Journey of Quality Management with Test Cases
Quality Management (QM) is a crucial aspect of any successful business, but for beginners, the labyrinth of its concepts can be daunting. One fundamental pillar in this realm is the ‘Test Case.’ A test case is more than just a procedure; it’s the blueprint for ensuring your product or service meets its designed quality. But why are test cases so vital? Let’s dive into the world of test cases and unravel their importance in maintaining and enhancing the quality of your projects.
A Personal Tale: The Chaos of Ignoring Documented Test Cases
Navigating the world of quality assurance without a map can be a harrowing experience, as I learned in a company that lacked documented test cases. Initially, the existing QA team, seasoned and skilled, seemed to manage well, relying on their memory and experience, until it didn’t. The cracks in this approach became glaringly evident when we faced two critical situations.
First, the sudden departure of a seasoned QA engineer left us in disarray. This individual, a repository of unwritten knowledge, had carried out complex tests effortlessly, but without documentation, his departure created a vacuum. We scrambled to reconstruct his methods, facing delays and quality issues – a stark reminder of the fragility of relying on implicit knowledge.
The second challenge arose with the arrival of a new QA engineer. Eager but inexperienced, she struggled immensely to grasp the nuances of our testing procedures. The absence of clear, documented test cases meant she had to rely on piecemeal information and constant guidance from overburdened colleagues. This slowed her integration into the team and highlighted the inefficiencies and risks of not having structured, accessible test case documentation.
These experiences taught me a critical lesson: the indispensable role of well-documented test cases in preserving organizational knowledge and facilitating new team members’ smooth onboarding and growth in Quality Management.
Breaking Down Test Cases: The Essential Components Explained
So, what exactly is a test case? In simple words:
A test case is a set of actions executed to verify your product or service’s particular feature or functionality.
Of course, there is more to it, e.g., the entire topic of test automation or special test cases like performance or security tests. But let’s go with this simple definition of a test case for now.
Understanding the anatomy of a test case is crucial for anyone beginning their journey in Quality Management. A well-crafted test case is a blueprint for validating the functionality and performance of your product or service. Let’s dissect the essential components of a good test case:
ID (Identification): Each test case should have a unique identifier. This makes referencing, tracking, and organizing test cases more manageable. Think of it as a quick way to pinpoint specific tests in a large suite. This way, renaming a test case won’t blow your test plans or entire setups since the ID will stay the same.
Description: This briefly overviews what the test case aims to verify. A clear description sets the stage by outlining the purpose and scope of the test, ensuring everyone understands its intent. This description should be written in a way that can be easily understood, even by new colleagues.
Pre-conditions: These are the specific conditions that must be met before the test is executed. This can include certain system states, configurations, or data setups. Pre-conditions ensure that the test environment is primed for accurate testing.
Steps: This section outlines the specific actions to be taken to execute the test. Each step should be clear and concise, guiding the tester through the process without ambiguity. Well-documented steps prevent misinterpretation and ensure consistent execution.
Test Data: This includes any specific data or inputs required for the test. Providing detailed test data ensures that tests are not only repeatable but also that they accurately mimic real-world scenarios.
Expected Results: What should happen as a result of executing the test? This section details the anticipated outcome, providing a clear benchmark against which to compare the actual test results. The expected results are often listed for each test case step.
Status: Post-execution, the status indicates whether the test has passed or failed. It’s a quick indicator of the health of the feature or functionality being tested.
Each component plays a pivotal role in crafting a test case that is not just a document but a tool for quality assurance. They collectively ensure that each test case is repeatable, reliable, and effective in catching issues before they affect your users.
By understanding and implementing these components in your test cases, you lay a strong foundation for a robust Quality Management system, one that is equipped to maintain high standards and adapt to changing requirements.
Revamping Your Test Case Strategy: A Call to Action for Beginners
As a beginner in Quality Management, you might wonder, “Where do I start?” The first step is to review or establish your test case documentation strategy. Ensure your test cases are simple yet detailed enough to cover all necessary aspects. Regular reviews and updates to these documents are vital. Remember, a test case is not a static document; it evolves with your product. By systematically documenting test cases, you safeguard your product’s quality and build a resilient framework that can withstand personnel changes and scale with your project’s growth.
Conclusion
The journey to mastering test cases in Quality Management is ongoing. It’s time to rethink your approach if you haven’t taken test case documentation seriously. Implementing robust test case practices enhances your product’s quality and fortifies your team’s efficiency and adaptability. Embrace this change and take the first step towards quality excellence. Your future self will thank you.
Engaging Prelude: First Steps into Chaos – The Crucial Awakening
Envision a majestic ship representing a thriving organization sailing into the unpredictable seas of the corporate world. Each crew member, vibrant and brimming with potential, is eager to contribute to the journey ahead. However, without a guiding compass — Policies —the ship is left vulnerable to the capricious tides, risking deviation from its intended course.
The lack of well-established policies or inadequate communication thereof is akin to a ship sailing blindfolded, a precursor to disorder and potential downfall. These guiding principles are the bedrock of any organization, ensuring a steadfast journey through calm and tumultuous times, ultimately leading toward success and stability.
This exploration delves into the transformative power of well-implemented policies and their essential role in sculpting an organization’s destiny. Let’s embark on this enlightening journey, uncovering the significance of organizational policies, the chaos in their absence, and the pathway to a stable and prosperous future.
Chronicles of Chaos: A Tale of Turmoil – The Ripple Effect of Missing Policies
Once upon a time, there was a mix of excitement and dreams in a lively and growing company. But, like a ship sailing on the sea without a map, this company didn’t have enough rules to guide its journey. The employees were like sailors, trying their best to navigate, but they sometimes got lost without clear directions.
One day, chaos snuck in through a small mistake. Not knowing the rules about what could be shared, an employee tweeted something that should have stayed inside the company. This small action created big waves, like a storm in the sea, affecting everyone in the company. There was a rush to fix the problems, a storm that could have been avoided if there was a clear rule about using social media.
This isn’t just a single story. It’s like many tales of ships and sailors trying to find their way on the big sea without a map or compass. When there aren’t clear rules, or the sailors don’t know them, it’s easy to make mistakes and get into trouble.
Understanding and Managing Policies in a Company
Let’s start with the definition of a policy. What is a policy?
In the context of a business, a policy is a set of principles or rules that guide decision-making and behavior within the organization. These guidelines help maintain a consistent and organized approach, ensuring all employees are on the same page and working towards common goals.
Handling and Management of Policies
Effective policy handling and management require awareness, accessibility, clarity, approval by higher management, regular reviews, and designated ownership. Addressing the following questions can help ensure that policies are appropriately managed:
Is every employee aware of your policies?
Does every employee know where to find your policies? Are they all stored or linked from a single, accessible place?
Are your policies recognizable as such? Is the term “Policy” clearly indicated, perhaps on the cover page?
Are your policies approved or signed by higher management? Is it clear who approved them, in what role, and when?
Do your policies have versions? Can employees easily identify the latest version, or do you have several versions flying around?
Are your policies reviewed regularly? How old are your policies? Might they be outdated? Ideally, there should be a review at least once a year.
Do your policies have an expiration or next review date? Is this date clearly visible within the policy?
Does each policy have an owner? Whom to ask if there are questions about a policy? Is the owner’s name listed within the policy?
Communicating Policies
Communication is key when implementing policies. Ensuring that every employee is aware of and understands each policy is essential. This involves:
Evidence of Reach: Is there proof that every employee has received the policy, perhaps through email or other communication channels?
Training: Is training provided for each policy to ensure understanding?
Feedback Channel: Is there a way to collect and address questions, suggestions, or concerns regarding a policy?
Acknowledgment System: Is there a system in place where every employee has to acknowledge or sign that they have understood the policy?
Essential Policies and Their Purpose
Core Policies:
Anti-discrimination and Harassment Policy: Prohibits discrimination and harassment based on various factors and outlines procedures for complaints.
Equal Employment Opportunity Policy: Declares the company’s commitment to equal employment opportunity in all aspects of employment.
Workplace Safety and Health Policy: Demonstrates the commitment to a safe workplace and details safety procedures.
Sustainability/Environmental Policy: Outlines commitments to sustainable practices and environmental responsibility.
Confidentiality and Information Security Policy: Protects information and outlines handling procedures.
Data Protection and Privacy Policy: Details how personal data is collected, used, stored, and protected, both for employees and customers.
Conflicts of Interest Policy: Defines and outlines procedures for disclosing and resolving conflicts of interest.
Quality Policy: States the commitment to quality products and services.
Business Continuity Plan: Outlines how operations will continue during and after a disruptive event.
Code of Conduct / Ethics Policy: Establishes expectations for employee behavior and outlines consequences for violations.
Other Recommended Policies:
Drug-free Workplace Policy: Prohibits the use of illegal drugs and alcohol in the workplace.
Social Media Policy: Outlines expectations for social media use.
Internet and Email Usage Policy: Provides guidelines for appropriate use of company internet and email.
Leave Policy: Details policies on various types of leave.
Performance Evaluation Policy: Outlines the process for evaluating employee performance.
Compensation and Benefits Policy: Details the structure of compensation and benefits.
Signing Policy: Defines authorization for signing documents on behalf of the organization.
Customer Care Policy: Sets guidelines for interacting with customers and resolving issues.
Complaints Handling Policy: Outlines how customer complaints will be received, investigated, and resolved.
By addressing the above aspects, companies can ensure that their policies are effective, well-communicated, and understood, thus fostering a harmonious and productive work environment.
Blueprint for Brilliance: Crafting Your Policy Compass – Navigating Towards Organizational Success
Now that we’ve unlocked the mysteries of policies and understood their pivotal role, it’s time to craft your own policy compass. Start by assessing your existing policies, ensuring they are accessible, well-communicated, and understood by all. Develop a robust system for policy communication, training, and acknowledgment. Don’t forget to regularly review and update your policies to navigate the ever-changing business seas successfully.
Call to Action
Embark on your journey towards organizational excellence by fortifying your company with well-established and communicated policies. Set sail towards stability and prosperity, and watch your ship navigate smoothly through the corporate storm!
Conclusion
Navigating through the storm requires a sturdy ship, a skilled crew, and a reliable compass. In the world of business, policies are your compass, guiding you toward success and stability. Embrace them, communicate them, and watch your company sail towards a horizon of endless possibilities!
Remember, a ship in the harbor is safe, but that is not what ships are built for. Set sail, navigate through the storm, and discover the treasures that await with effective policies. Safe travels, dear reader, until our next enlightening adventure!
In today’s rapidly evolving business landscape, achieving and maintaining high-quality standards is more critical than ever. Organizations across industries realize the significance of having a dedicated leader to spearhead their quality initiatives. This is where the Chief Quality Officer (CQO) steps into the spotlight, redefining how businesses approach quality management.
The Birth of a Quality Champion
Imagine an organization with rapid growth, where several individuals were independently pushing for quality improvements. One team focused on obtaining certifications, another in R&D was striving to enhance test coverage, and yet another group diligently documented various processes. These were all commendable efforts, but they lacked coordination and operated independently, leading to duplicate work, information silos, unaddressed dependencies, and many missed opportunities.
Amidst this bustling ecosystem of well-intentioned but fragmented quality initiatives, a crucial element was conspicuously absent—a unifying leader who could weave these disparate threads into a single, robust rope of quality excellence. This leader was the Chief Quality Officer (CQO). Their role would be to align these scattered efforts, bridge the gaps, and steer the organization toward a cohesive and strategic approach to quality management.
The Role of the Chief Quality Officer (CQO)
Now that we’ve seen the pivotal role a CQO can play, it’s time to delve deeper into their responsibilities and contributions:
Defining the Chief Quality Officer (CQO)
In essence, a CQO is the guardian of quality within an organization. They oversee and implement quality management systems, ensure adherence to industry standards and regulations, and drive continuous improvement. The CQO is not just a title; it’s a commitment to excellence.
The Critical Responsibilities of a CQO
Quality Strategy Development: CQOs formulate and execute a comprehensive quality strategy aligned with the organization’s goals.
Compliance Assurance: They ensure the company adheres to all relevant quality standards and regulations.
Risk Management: Identifying and mitigating quality-related risks is a core aspect of their role.
Quality Culture Promotion: CQOs foster a quality culture throughout the organization, from the boardroom to the front lines.
Why Every Organization Needs a CQO
The need for a CQO becomes evident when you consider the competitive advantages they bring:
Enhanced product/service quality
Improved customer satisfaction and loyalty
Reduced operational costs and waste
Minimized quality-related crises and recalls
To be fair, not every organization needs a CQO from the beginning. Many companies start with a quality manager, taking care of all aspects of quality management. Hence the need for the tasks and responsibilities is still there. And soon, the need will arise to have a dedicated CQO role, especially for larger and fast-growing organizations.
Implementing Quality Excellence
Now that you understand the significance of a CQO let’s explore how you can introduce this role in your organization and embark on a journey toward quality excellence:
How to Introduce a Chief Quality Officer (CQO) in Your Organization
Assess your organization’s current quality maturity.
Define the scope and responsibilities of the CQO role.
Recruit or designate a qualified individual for the position.
Ensure top-level support and commitment to quality initiatives.
Steps for Success: Building a Quality-Centric Culture
Foster a culture that prioritizes quality at every level.
Invest in employee training and development.
Establish key performance indicators (KPIs) to measure quality performance.
Encourage collaboration and cross-functional quality teams.
Your Roadmap to Quality Transformation
Continuously monitor and assess the effectiveness of your quality initiatives.
Embrace technology and data-driven quality management.
Adapt to changing industry regulations and customer expectations.
Celebrate and recognize quality achievements within your organization.
Incorporating the Chief Quality Officer (CQO) into your organizational structure can be a game-changer, positioning your company as a leader in quality excellence. Take the first step on this transformative journey and elevate your organization’s quality leadership.
In the ever-evolving landscape of business, the quest for profitability is unceasing. Every organization strives to maximize its Revenue while minimizing costs. This journey often revolves around the concepts of the “top line” and the “bottom line.” Today, we’ll explore how quality management can be the catalyst for boosting the often-overlooked bottom line of your company. Welcome to the world of “Quality and the Bottom Line.”
The Quality Shift That Transformed My Company
Before we dive into the mechanics of quality and its impact on the bottom line, let me share a personal story. A few years ago, I found myself at a crossroads with my company. We were performing decently, but something was amiss. We struggled with customer complaints, costly rework, and defects that seemed to haunt our products.
A major client walked away one fateful day due to persistent quality issues. This was a wake-up call that shook the foundation of our organization. We had been fixated on increasing our top-line Revenue, offering more features and services to attract customers. Little did we know that our blind pursuit of the top line compromised the bottom line in the process.
Quality and the Bottom Line: A Winning Equation
To understand the impact of quality on the bottom line, let’s first clarify these terms:
Top Line vs. Bottom Line in Companies – Definitions
The “top line” represents your company’s Revenue. It’s the money flowing in from sales, contracts, and other income sources. On the other hand, the “bottom line” is your company’s net profit after deducting all expenses, including operating costs, taxes, and interest.
Now, here’s where the magic happens:
The Right Features Can Command a Higher Price and Still Attract Customers
Something remarkable occurred when we shifted our focus from cramming more features into our products to ensuring that the existing ones were flawless. Customers appreciated the quality and were willing to pay a premium for it. Quality became a differentiator, allowing us to command higher prices in the market.
Being Free from Deficiencies Results in Higher Quality and Less Total Costs
Quality management isn’t just about aesthetics; it’s about ensuring that your product or service meets or exceeds customer expectations. By eradicating defects and deficiencies, we reduced our costs significantly. Scrap, rework, warranty claims, and customer complaints dwindled, saving us money and time.
Quality Must Exist Throughout the Entire Value Chain
Quality isn’t the sole responsibility of the production or service delivery team. It must permeate every facet of your organization, from procurement and design to marketing and customer support. A quality-centric culture ensures everyone understands their role in maintaining and enhancing quality.
Right Features –> Increased Quality –> Increased Revenue (Top Line)
Focusing on quality and perfecting our product attracted more customers willing to pay higher prices. This translated directly into increased Revenue, addressing the top-line aspect of our business equation.
Less Deficiency –> Fewer Defects –> Higher Quality –> Less Costs
Our commitment to quality resulted in fewer defects, reduced rework, and diminished customer complaints. This improved the quality of our products and lowered our operating costs significantly.
Higher Revenue + Less Costs –> More Profit (Bottom Line)
The result? A healthier bottom line. Higher Revenue combined with reduced costs translated into increased profits, making our business more sustainable and resilient.
Taking the First Step – Implementing Quality for Profit
Now that you understand the powerful impact of quality on the bottom line, it’s time to take action. Here are the steps to get you started on your quality management journey:
1. Assess Your Current Quality Practices
Begin by evaluating your current quality management practices. Identify strengths and weaknesses in your processes, procedures, and culture.
2. Identify Areas for Improvement
Pinpoint areas where improvements are needed. Look for recurring quality issues, customer complaints, and costly defects.
3. Invest in Quality Training and Tools
Allocate resources for quality training and invest in the right tools and technology to support your quality initiatives.
4. Cultivate a Quality-Centric Culture
Foster a culture of quality throughout your organization. Ensure that every employee understands their role in maintaining and enhancing quality.
5. Measure and Monitor Quality Metrics
Establish key performance indicators (KPIs) to measure the impact of your quality efforts. Regularly monitor these metrics and make data-driven decisions to improve continually.
Your Call to Action: Start Your Quality Transformation Journey
Don’t let your bottom line suffer due to neglecting quality. Embrace quality management as a strategic approach to boost your profits. Start your quality transformation journey today, and you’ll soon witness the remarkable impact it can have on your business’s bottom line.
In conclusion, quality isn’t just a buzzword; it’s a profit driver. By aligning your organization with quality principles, you can enhance your top line, reduce costs, and ultimately maximize your bottom line. Quality and profitability are intertwined, and it’s time to harness this synergy for your business’s success.
The Allure of Consistency: Why Maintainability Matters
In today’s fast-paced world, products and services must be reliable, robust, and resilient. But more than that, they need to be sustainable. That’s where maintainability comes in. It’s the unseen force that ensures our favorite tools, platforms, and systems keep running smoothly, day in and day out.
Maintainability, at its core, measures how easily a product or system can be preserved in its functional state. It answers questions like: How quickly can we respond to unforeseen issues? How efficiently can updates be implemented? And how effectively can we avoid future problems?
Here’s why maintainability is so much more than a mere operational necessity:
Cost Efficiency: Initial development and deployment might seem like the most expensive aspects of a product, but long-term maintenance can significantly add to these costs. If a system is designed with maintainability in mind, these ongoing costs can be substantially reduced. Fewer person-hours, fewer resources, and less downtime translate directly into cost savings.
User Trust: We live in an era of instant gratification. If a system or service breaks down, users expect quick resolutions. Systems that are maintainable foster user trust because they assure users that issues will be resolved promptly and effectively. And in the digital age, trust is the currency that drives loyalty.
Flexibility & Adaptability: Markets change. Technologies evolve. A maintainable system is, by design, more adaptable to these changes. It allows for easier upgrades, smoother integrations, and quicker pivots, ensuring the system remains relevant and effective in the face of change.
Longevity: In the business world, it’s not just about creating the next big thing; it’s about ensuring that the ‘big thing’ lasts. Maintainability extends the lifespan of a product or system. When products last longer, businesses can maximize ROI and build a more substantial brand reputation.
Reduced Risk: Every moment a system is down, there’s a risk—lost revenue, unsatisfied customers, and potential data breaches. With higher maintainability, these downtimes are reduced, mitigating the associated risks.
In essence, maintainability isn’t a feature you add after the fact; it’s a philosophy you embed from the outset. It’s about foreseeing tomorrow’s challenges and designing systems today that can weather them. In the world of quality management, maintainability isn’t just a term—it’s the embodiment of foresight, adaptability, and commitment to lasting quality.
A Painful Oversight: How Ignoring Maintainability Cost Us
Every product journey has its highs and lows. While we often revel in the success stories, it’s the mistakes and oversights that teach us the most valuable lessons. Our story is one such lesson, a poignant reminder of the price we pay when we overlook the essence of maintainability.
It all started with a product we believed was a masterpiece. Months of planning, development, and testing culminated in a system we were genuinely proud of. But pride, as they say, often precedes a fall.
Not long after launch, feedback from a customer hinted at an underlying issue—a glitch that seemed minor on the surface. Optimistically, we thought it would be a quick fix. But as we dove deeper, the ramifications of our oversight became painfully clear.
Duplication Dilemma: The product’s codebase was riddled with duplications. What seemed like shortcuts during development now stood as barriers to efficient troubleshooting. This meant that an error wasn’t isolated to one part but echoed across multiple facets of the product.
The Domino Effect: Fixing the reported error was time-consuming, but that was just the tip of the iceberg. The error kept reappearing in different guises because the fix wasn’t uniformly applied due to the duplicated code. Each recurrence chipped away at our team’s morale and, more importantly, our reputation with the customer.
Customer Dissatisfaction: In today’s interconnected world, a single customer’s dissatisfaction can ripple out, affecting perceptions and trust. Our lack of maintainability didn’t just result in a recurring error; it tarnished our brand’s image. What could’ve been a minor hiccup transformed into a lingering issue that cost us not only time and resources but also customer trust.
The Reality Check: This experience was a wake-up call. It underscored the importance of designing products with maintainability as a cornerstone, not an afterthought. Short-term conveniences can lead to long-term challenges, and in our quest for quick solutions, we inadvertently compromised on the product’s foundational quality.
The silver lining? Mistakes, as painful as they might be, pave the way for growth. This episode propelled us to reevaluate our processes, placing maintainability at the forefront of our development philosophy.
Beyond Quick Fixes: The Science of Maintaining Systems
Every robust system or product isn’t just a result of innovative design but also a testament to meticulous maintainability practices. But to truly appreciate its essence, we must understand the nuances of maintainability and the tools that drive it.
Understanding Maintainability: It’s more than just a buzzword; maintainability is the art and science of ensuring a system’s long-term reliability. But how exactly do we measure and optimize it?
Preventive Maintenance: Proactivity is the hallmark of preventive maintenance. By regularly analyzing and updating systems, potential pitfalls are identified and addressed ahead of time. The aim? Reduce failures and boost system longevity.
Corrective Maintenance: No system is flawless, but how quickly and effectively it recovers from setbacks indicates its maintainability. Corrective maintenance is all about swift and efficient troubleshooting, with the Mean Time To Repair (MTTR) being a key performance indicator.
Harnessing the Power of Design: While design dictates user experience, it also profoundly impacts maintainability. Systems conceived with maintenance in mind are:
Easier to update.
Streamlined for integrations.
More straightforward to troubleshoot.
Tools of the Trade: Prevention at Its Best:
Static Code Analysis: One of the first lines of defense against maintainability issues. Tools that perform static code analysis meticulously comb through codebases without executing the program. They pinpoint problematic areas, whether it’s duplicated code or convoluted logic, that could become a headache down the line.
Code Complexity Metrics: Understanding the complexity of the code can provide insights into potential maintenance challenges. Complex code might be harder to maintain and more prone to errors. Tools that measure code complexity help developers streamline and simplify, promoting cleaner, more maintainable code.
Regular Code Reviews: Instituting regular code reviews within teams can identify potential issues before they escalate. These peer reviews ensure code quality, consistency, and maintainability.
A Delicate Dance of Availability and Maintainability: Both these aspects are pillars of a product’s quality. While availability ensures users have access when needed, maintainability guarantees the system remains reliable over time.
Reimagining Development: In the ever-evolving landscape of technology, the focus isn’t just on creating; it’s about sustaining. With the right tools and a proactive approach, maintainability takes center stage, ensuring products are innovative and enduringly reliable.
Your Action Plan: Making Maintainability A Habit
Maintainability isn’t a one-time endeavor; it’s a continuous commitment. It’s not just about creating systems that function efficiently today but crafting legacy systems that will be hailed for their reliability years down the line. Here’s a structured plan to make maintainability a habitual part of your development process.
1. Equip with the Right Tools: Invest in the essentials.
Code Analyzers: Delve into tools like SonarQube, SAST or Coverity. Their strength lies in pinpointing issues and offering actionable insights to rectify them.
Adopt CI Platforms: Embrace platforms like Jenkins or Travis CI to seamlessly integrate every new code change without disrupting existing functionalities.
2. Pledge to Pristine Code: Quality over quantity always.
Adopt refactoring as a regular practice to keep code lean and efficient.
Stick to recognized coding conventions, ensuring every line written echoes clarity.
Prioritize documentation. It’s the bridge between current developers and future maintainers.
3. Champion Continuous Learning: Maintainability evolves, and so should you.
Stay updated with the latest best practices through workshops, training sessions, or online courses.
4. Valuing Feedback as Gold: Constructive criticism is a developer’s best friend.
Encourage feedback loops from peers, users, or third-party audits. It’s the compass that points to areas ripe for improvement.
5. Map Out Maintenance: A well-planned path ensures fewer hiccups.
Craft a detailed maintenance roadmap. From regular system checks to updates, ensure every step is well-planned and executed.
The Starting Line: For those still on the fence about maintainability, let our earlier story serve as both a cautionary tale and an inspiration. Start today; integrate maintainability into every phase of your development process.
By making maintainability a regular habit, you’re ensuring seamless operations today and setting the stage for a legacy of reliability. With the roadmap above, the journey towards sustained excellence begins.
Unlocking a Core Metric: The Essence of Availability
In the vast business world, many metrics and measures help determine success. Sales figures, customer reviews, growth rates – these are all critical. However, nestled among these high-profile metrics is a quieter yet incredibly impactful measure known as “Availability.” But what exactly is it?
At its simplest, availability assures that a product, service, or system will be there when needed. It’s like expecting the sun to rise every morning or your favorite coffee shop to be open when you need that early-morning caffeine fix. Imagine a scenario where you walk up to the coffee shop, and it’s unexpectedly closed. That disappointment, that disruption to your routine – that’s what happens when availability falters in the business world. For a company, it could mean a service not being accessible, a website crashing during a peak sales hour, or a product failing when a customer needs it most.
In essence, availability isn’t merely about uptime; it’s about trust, reliability, and a business’s commitment to its customers. As we delve deeper into this topic, we’ll explore its nuances, its importance, and why businesses, big or small, should prioritize it.
The Four 9’s Epiphany: A Glimpse into High-Stakes Availability
Imagine for a moment, a bustling city that never sleeps. People in this city go to restaurants, hairdressers, theaters, bars, etc. There, they pay cash or with credit cards. Hence, there is an endless flow of payment transactions every single second, day in and day out. People would be depressed if such a transaction fails or even crashes. Imagine your credit card is declined in a restaurant, and you don’t have cash. Or even worse, you draw money from an ATM, but the system crashes before you get the money out of the machine, but your account has been charged already. Not good. Hence, you want the involved system to be available, always. What if you learned that your bank promises to run its servers or ATMs 99.9999% of the time? It’s a bold promise, almost hard to believe. That’s roughly half a minute of downtime in an entire year!
Behind this promise lies an army of dedicated professionals: engineers, technicians, and customer service staff, all working around the clock. These individuals ensure that there is a lot of redundancy for the servers, that maintenance windows are scheduled and performed without interrupting the service, that security updates are installed regularly, and that all possible scenarios are tested sufficiently. The goal isn’t just about keeping the service running; it’s about upholding a commitment to the millions who rely on it.
This payment story vividly illustrates the lengths some sectors go to ensure availability. The magic of the four 9s isn’t just in its impressive statistic; it’s in the trust it builds with every customer who uses the service, confident that the payments are booked correctly and without interruptions. And just like our payment example, the emphasis is on the importance of availability, the dedication to ensuring it, and the implications of failing to meet those standards. And luckily, usually it doesn’t need that many 9s to build up that customer confidence and trust.
The ABCs of Availability: Beyond Just Uptime
At its heart, availability is a commitment, a promise that businesses make to their stakeholders. But how do we measure such a commitment? Like most promises, some science and math are behind it. Let’s break it down using easy-to-understand analogies:
What Does Availability Really Mean? Think of availability as a shop that you like visiting. If it’s open every time you go there, it has high availability. If it’s often closed unexpectedly, its availability is lower. In technical terms, it’s the amount of time something works as expected compared to the entire time it should be.
Understanding Operational Availability: Imagine you have a toy that works for 10 hours but then needs a 1-hour break to recharge. This toy’s ‘Operational Availability’ would be the time it works without needing a break compared to the total time it’s been used. In numbers, this would be calculated as:
MTBF (Mean Time Between Failures) divided by the sum of MTBF and MDT (Mean Down Time). It measures how often something works compared to the combined time of working and being broken.
In our toy example, this would be 0,9 or 90% availability.
Diving into Intrinsic Availability: There is another type of availability used quite often. It’s called “Intrinsic Availability”. In contrast to “Operational Availability,” we consider the repair time only here. Scheduled downtimes and maintenance are not considered since the product, service, or system would be technically available. It is not broken, just not used right now to do maintenance. Hence, it is just a different way to look at availability.
In terms of a formula, this is MTBF divided by the sum of MTBF and MTTR (Mean Time To Repair).
Intrinsic Availability = MTBF / (MTBF + MTTR)
Coming back to our toy example. The charging time is not considered as repair time. Hence the Intrinsic Availability would be 100% if no repairs would be necessary at all.
There are even more types of availability, e.g., Technical Availability, Inherent Availability, or Achievable Availability. But I’ll skip those here for now.
Important would be that you know which kind of availability you want to measure and why. And, of course, how to interpret those numbers.
By understanding these terms and concepts, businesses can pinpoint where they stand regarding their commitment to stakeholders. They can see how often their systems or products might falter and how quickly they can recover when they do. In essence, availability isn’t just a buzzword; it reflects a business’s resilience and reliability.
Making Every Second Count: The Business Imperative of Availability
Availability is often under the spotlight in the vast web of business operations. This isn’t just because of its technical significance but its profound business implications. Here’s why every tick of the clock matters and how businesses can capitalize on the promise of availability:
The Cost of Downtime: Let’s picture a buzzing online store. Imagine it suddenly crashing on Black Friday. Every moment it’s down, potential sales evaporate. Beyond just immediate losses, such incidents can deter future customers. Downtime, in essence, hits the business pocket both in the present and in potential future revenues.
Building Trust through Reliability: Consider a bank ATM. If it fails to dispense cash occasionally, users become wary. The more reliable an ATM, the more people trust that bank. Regardless of their sector, businesses earn their customers’ trust by ensuring consistent availability. It signals to the customer that the company is dependable and that they can count on it.
Reputation: The Silent Stakeholder: In our interconnected digital age, news travels fast. If a service is frequently unavailable, it doesn’t take long for this information to spread, potentially damaging a company’s reputation. A solid reputation can take years to build but only moments to tarnish.
Stepping Up to the Challenge: So, how can businesses navigate these waters? Regular maintenance is a crucial first step. Many disruptions can be avoided by proactively identifying potential issues and rectifying them. Investing in robust infrastructure and technologies is another essential aspect. Such investments not only bolster availability but can also offer competitive advantages in the market. Lastly, it’s pivotal to maintain open channels of communication with customers. By understanding their needs and feedback, businesses can better align their availability goals with customer expectations.
In the grand theater of business, where various elements play their part, availability stands out as a silent guardian. It ensures smooth operations, builds trust and fortifies reputation. For companies aspiring to lead in their domains, prioritizing availability isn’t just an option; it’s an imperative.
The Hidden Puzzle of Success: Discovering Roles in Quality Management
Quality management isn’t just about products or processes; it’s about people. It’s about individuals’ roles in ensuring that an organization’s products meet the highest standards. From the Chief Quality Officer (CQO) to the Quality Architect, understanding the roles in quality management is the secret to a thriving, successful organization, especially in larger companies.
But what are these roles, and why do they matter? Imagine a symphony orchestra. You have the conductor, first violin, percussionists, and many other unique roles. Each has a specific function, yet all work together to create beautiful music. The world of quality management is like that orchestra. Without understanding the roles, without knowing who plays what part, the music becomes noise, and quality becomes chaos. The absence of clear roles can lead to confusion, inefficiency, and failure to meet quality objectives.
So, let’s unravel this hidden puzzle, explore the different roles in quality management, and understand how they contribute to building a culture of quality excellence. Whether you’re just starting to build your quality team or looking to optimize an existing one, knowing these roles is the key to unlocking success.
From Chaos to Quality: My Journey Through Undefined Roles in Quality Management
Once, I worked in a company where roles were as murky as a foggy day. Responsibilities were unclear, and no one felt responsible for anything regarding quality. The chaos was not just a hurdle; it was a brick wall. We stumbled, we fell, but most importantly, we learned.
I remember the days when team meetings felt like a whirlwind of confusion, with everyone looking at each other, unsure who was supposed to take charge of different quality aspects. Projects were delayed, quality was compromised, and frustration was common. Without defined roles, tasks were duplicated or overlooked, and accountability was lost in the shadows.
In a growing company, especially in the bustling software development sector, defining roles in quality management is not just helpful; it’s a lifeline. Clear roles create a roadmap, showing everyone in the organization who is responsible for what. They create alignment, foster collaboration, and build a culture of accountability and excellence.
When roles are clearly defined, the chaos turns into order, confusion into clarity, and frustration into motivation. The transformation isn’t overnight, but with the proper structure, the journey from chaos to quality is not only possible; it’s inevitable. My experience taught me that understanding and implementing the different roles in quality management is akin to laying down the foundation of a building. Without it, everything can crumble.
Building the Dream Team: Essential Roles in Quality Management Explained
Chief Quality Officer (CQO): The CQO is the visionary leader of the quality management system. They are responsible for defining the quality strategy and ensuring alignment with the organization’s overall business goals. By setting quality objectives and policies, they build a culture where quality is a core value. In large organizations, the CQO often collaborates with other C-level executives to integrate quality into every aspect of the business, making quality a part of the organization’s DNA.
Quality Managers:Quality Managers are the implementers and guardians of quality standards and processes within different departments or across the entire organization. They translate the quality strategy into actionable plans, coordinate quality improvement initiatives, and work closely with other managers to ensure compliance with quality requirements. Quality Managers also monitor performance, analyze data, and initiate corrective actions when needed. They are the generals on the ground, leading quality efforts on a day-to-day basis.
Quality Architect: The Quality Architect is responsible for designing the overall quality framework for products and processes. They develop standards, methodologies, and tools that support the organization’s quality goals. In software development, a Quality Architect may create testing strategies, design quality metrics, and select appropriate tools and technologies. They ensure that quality is integrated into the design and development process, laying the foundation for excellence from the very beginning.
Quality Engineers and Analysts: These roles are the foot soldiers in the quality army, carrying out the daily checks and tests to ensure that products and processes meet the established standards. Quality Engineers develop and execute testing procedures, analyze results, and work with development teams to address defects or issues. Quality Analysts often focus on data analysis, identifying trends, and supporting continuous improvement efforts. Together, they play a vital role in maintaining the organization’s quality integrity.
Compliance and Regulatory Experts: Compliance and Regulatory Experts focus on quality management’s legal and regulatory aspects. They ensure the organization’s products and processes comply with relevant laws, regulations, and industry standards. They monitor regulation changes, conduct audits, and collaborate with other teams to ensure that the company’s quality management system aligns with all legal requirements. Their role is crucial in industries where regulatory compliance is stringent and often changing, such as healthcare, finance, or automotive.
For Small to Large Growth:
Of course you do not need all thos roles right from the beginning. Especially in smaller companies some of those roles are combined in one person. But how to start building up a quality organization? Here some guidelines:
Start with a Quality Manager. In smaller setups, a Quality Manager can cover various aspects.
Add Quality Engineers and Analysts. As you grow, the troops become essential.
Bring in Compliance Experts. You’ll need them as regulations become more intricate.
Invest in a Quality Architect. They will help shape the bigger picture.
Finally, appoint a CQO. This role will bring everything together.
These roles form the backbone of a robust quality management system, ensuring that your organization’s quality meets standards and exceeds them.
Taking the First Step: How to Implement Roles in Quality Management in Your Company
Embarking on this journey can be daunting, but it’s necessary. Here’s a simple roadmap to start:
Assess Your Current Situation: Identify where you are and what you need.
Define Roles Clearly: Job descriptions and responsibilities should be crystal clear.
Train and Hire as Needed: Building the team might require new hires or training existing staff.
Regularly Review and Adjust: Like quality itself, the roles in quality management should be dynamic.
Remember, it’s not just about filling positions but finding the right people. The roles in quality management are like pieces of a puzzle, each unique yet fitting together to create a picture of excellence.
You can start today, assess your quality team, understand where you need to improve, and make the first step toward unlocking excellence through clearly defined roles in quality management. Your path to success is just a decision away!
Recently a former Apple employee told me that they had a list of rules for success printed on the back of the company badge. This badge everyone is carrying around all the time, and hence you can’t even avoid getting reminded of those rules every now and then. I very much like that idea.
Here are the rules I would use in the future. They are based primarily on the Apple rules, and I made some minor modifications.
Let go of the old, make the most of the future
Always tell the truth, we want to hear the bad news sooner than later
The highest level of integrity is expected, when in doubt, ask
Learn to be a good businessperson, not just a good salesperson or engineer
Everyone sweeps the floor
Be professional in your style, speech, and follow-ups
Listen to the customer, they almost always get it
Create win/win relationships with customers, partners, employees
Look out for each other, sharing information is a good thing
Don’t take yourself too seriously
Have fun, otherwise, it’s not worth it
Having a set of rules for success, like the ones mentioned above, can be incredibly helpful. These guidelines help to remind us regularly of our goals and values as well as how we should interact with each other both professionally and personally. It is important that these rules are visible so they stay top-of-mind – whether it’s written on the back of your badge or posted around your office space. Ultimately, having clear expectations helps everyone work together more effectively towards common objectives.
Join our newsletter and become a part of our ‘Quality Management Club’, to not miss future blog posts.
Have you ever used a piece of software that wasn’t working as expected? Chances are, it was due to software bugs. But what exactly is a software bug and how do they occur?
In this article, we’ll explore the concept of software bugs and explain why they exist in plain English. We’ll discuss common causes for these issues, the process for debugging them, and ways to prevent future problems from occurring. By the end of this article, you should have a better understanding of software bugs so that you can avoid them when developing your applications.
What is a Software Bug and How Do They Occur
When it comes to software development, software bugs are one of the most common issues that developers will encounter. A software bug is an error or flaw in a program’s code that causes it to produce unexpected or unintended results. This could range from a minor inconvenience in functionality to a major security breach and data loss or application crash.
Software Bug
Software bugs are most commonly the result of human error during the development process. This could include incorrect syntax in code or missing parameters in a function. Other times, software bugs are caused by design flaws, or environmental issues such as operating system incompatibility, or hardware failure. Whatever their origin, software bugs can be incredibly difficult to diagnose and fix, leading to frustration for both developers and users.
The good news is that debugging software bugs can be a straightforward process with the right approach and tools. By understanding the basics of what causes software bugs and how to find them, developers will have the knowledge they need to create robust applications.
Common Causes of Software Bugs
Common causes of software bugs can be divided into two main categories: human errors and environmental issues. Human errors include incorrect syntax in code or missing parameters in a function and are often the result of poor communication between developers or lack of experience. Other common causes of software bugs include design flaws, such as inadequate testing and validation, or the use of outdated or incompatible technology. Environmental issues may include the use of old operating systems, hardware flaws, and differences in coding standards between different software platforms.
Poor Communication between Developers: If developers lack clarity about their roles or fail to communicate effectively with one another, it can lead to incorrect syntax in code and missing parameters within functions that go unnoticed until the software is released.
Lack of Experience: Even experienced developers may overlook certain aspects of the code which can lead to bugs in the software.
Inadequate Testing and Validation: Proper testing and validation are necessary to ensure that all features are working as intended, but often gets overlooked during development.
Outdated or Incompatible Technology: Using outdated technology can lead to compatibility issues while using incompatible versions of technology can cause unexpected errors in the code.
Old Operating Systems: Running software on an old operating system can lead to bugs if the software isn’t designed for that particular OS version.
Hardware Flaws: Hardware flaws can lead to errors in the code if they are not caught during the development process.
Incorrect Logic: Poorly written logic can lead to bugs in the software, such as infinite loops or incorrect output.
Memory Leaks: Memory leaks occur when a program fails to free unused memory which can lead to errors or failures.
Race Conditions: Race conditions occur when two or more processes try to access the same resource simultaneously, leading to unexpected results.
Differences in Coding Standards: Different software platforms have different coding standards which can lead to compatibility issues if not taken into account during development.
The Debugging Process for Resolving Issues
The debugging process for resolving software bugs can be broken down into several key steps. The first step is to identify the bug, which involves examining the code where the bug is located and investigating any related information. This step can involve running a debugger or analyzing log files to pinpoint the precise cause of the issue. Once the bug has been identified, the next step is to find an appropriate solution. Depending on the complexity of the issue, this could involve writing new code or making changes to existing code.
Once a solution has been found, it’s important to test it thoroughly before deploying it in production. This can include using automated testing tools or manual testing with sample data sets. If necessary, additional tests can be conducted in a staging environment before deploying across all systems. After successful testing, the solution should be implemented in all environments and monitored for any unexpected behavior or errors that may arise due to different environmental conditions.
Debugging software bugs can also require further investigation if complex issues are encountered or if environmental conditions are changing rapidly. In such cases, additional diagnostics may be required such as profiling and performance analysis to identify potential problems in the codebase that may have caused the bug initially. It’s also important to keep track of fixes and solutions so they can easily be referred back to when similar issues arise in future applications or projects.
Finally, once a software bug has been resolved it’s important to document everything that was done during debugging so that future developers are better prepared when faced with similar issues in their own projects. Documentation not only serves as a reference for other developers but also helps improve quality assurance processes for future projects by providing feedback on what went wrong and why certain solutions were chosen over others.
Ways to Prevent Future Problems from Occurring
There are several ways to prevent future software bugs from occurring. One of the most important steps is to ensure that all code is thoroughly tested before it is deployed. Automated testing tools can be used to quickly detect errors and identify issues that may not be visible in manual testing. Additionally, developers should strive to create well-structured and documented code with clearly defined parameters which can help reduce the chances of introducing unexpected errors.
It’s also important to ensure that the right technologies are being used for each application or system. This includes selecting compatible versions of databases, operating systems, frameworks, and other components. In some cases, using outdated or incompatible versions can lead to unexpected results which can cause software bugs. It’s also essential to make sure that any hardware components used in a system are free from flaws as this could lead to issues in the codebase.
In addition, proper debugging techniques should be employed when developing software. Debugging tools such as breakpoints, logging statements, and stack traces can provide valuable insight into the execution process and help identify potential issues before they become more serious problems. Additionally, developers should keep track of changes made during debugging so any unforeseen issues arising from them can be quickly identified and resolved before deployment.
Finally, systematic problem-solving strategies should be employed when debugging complex issues or making changes in existing codebases. This involves breaking down complex problems into smaller tasks which can then be solved systematically one at a time using deductive reasoning while documenting all findings along the way. Doing this helps avoid overlooking important details and provides a clear roadmap for fixing software bugs in an efficient manner without introducing new ones into the codebase inadvertently.
Wrapping Up – Understanding the Basics of Software Bugs
Software bugs can range from minor errors in functionality to significant breaches in security and data loss. This means it is important to understand how these bugs manifest and how they can be prevented or resolved quickly and effectively.
Developers should ensure that the code is thoroughly tested and debugged before deployment. Automated testing tools can be very helpful in detecting errors quickly and avoiding unexpected results. Additionally, developers should strive to create well-structured and documented code with clearly defined parameters which can help reduce the chances of introducing new software bugs. Additionally, it’s important to use compatible versions of databases, operating systems, frameworks, and other components as well as make sure that any hardware components used are free from flaws. Finally, developers should employ systematic problem-solving strategies when debugging complex issues or making changes in existing codebases.
By understanding the basics of software bugs and implementing proper testing and debugging techniques, software developers can create applications that are more reliable and secure. This ultimately leads to better customer experiences and improved satisfaction.
Conclusion
Software bugs can be a major source of frustration for developers and customers alike. However, with the right tools, techniques, and strategies in place, software bugs can easily be avoided or fixed quickly. By understanding how these issues manifest and taking steps to ensure that code is thoroughly tested before deployment, it’s possible to create more reliable applications that provide better user experiences overall. With this knowledge under your belt, you should now have all the necessary information needed to tackle any software bug-related challenges head-on!
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.