It was supposed to be a routine rollout. Nothing fancy. Just another step in a multi-phase digital transformation. The project team was confident. “We’ve done this before,” they said. “It should be fine.”
Only this time, it wasn’t. Because this time, they were flying blind with their eyes wide open.
Parallel launches across regions. Overlapping system updates. A handful of key engineers tied up in a second initiative. A predictive analytics model had already flagged this constellation as high risk. The warning dashboard flashed red.
But the team? They felt good.
Gut feeling said: smooth sailing. Data said: brace for impact.
Guess who was right?
Two hours into the rollout, user support channels lit up. Latency in the EU region. Inconsistent behavior in the APAC login system. And a classic domino effect: one delayed sync cascaded into three customer-facing outages.
Was this unforeseeable? Not even close. It was practically scripted. The early warning dashboard had simulated this failure path weeks in advance. But because it was “just a model” and “we’ve always managed before,” the data was ignored.
The dangerous illusion of experience
In software delivery, a special kind of overconfidence arises from success. When you’ve survived ten chaotic launches, you start believing you’re invincible. The gut starts feeling smarter than the numbers.
But let’s be blunt: your gut is not a risk management tool. It’s a storytelling machine, not a sensor. It remembers the wins and conveniently forgets the close calls.
Data, on the other hand, has no ego. It doesn’t care how many late-night war rooms you survived. It just tells you what’s likely to happen next, based on patterns you’d rather not relive.
And yet, in critical moments, many teams still fall back on hope. Or worse: consensus-driven optimism. “No one sees an issue, so we should be good.” That’s not alignment. That’s groupthink with a smile.
From feelings to foresight: build your risk radar
So, how do you stop your team from betting the farm on good vibes?
Simple: give them a better radar. And make it visible.
Enter the risk heat map and early-warning dashboard. These tools aren’t just fancy charts for the PMO. They’re operational x-ray glasses:
Risk heat maps visualize where complexity and fragility intersect. You see hotspots, not just in systems, but in dependencies, staffing, and timing.
Early-warning dashboards highlight leading indicators: skipped tests, overbooked engineers, unacknowledged alerts, and delayed decision-making. All the invisible signals your gut can’t process.
And here’s the kicker: when these tools are part of your regular rituals—planning, retros, leadership syncs—they stop being side notes. They become part of how you think.
Because when risk becomes visible, it becomes manageable. And when it’s manageable, it’s not scary.
So go ahead, listen to your gut. But if your dashboard is screaming, maybe it’s time to stop hoping and start acting.
Quality is not just what you build. It’s how you prepare.
A few months ago, a product team proudly told us they had reached “CI/CD nirvana.” They were pushing updates to production multiple times a day—zero friction, total speed.
Until they broke production.
It wasn’t just a glitch. One bad release triggered cascading failures in dependent services. It took them three full days to stabilize the system, get customer support under control, and recover user trust. Exhausted and embarrassed, the team quietly rolled back to a safer cadence.
This isn’t unusual. Teams chasing speed often treat quality gates as enemies of velocity. They see checks like code coverage thresholds, linting rules, or pre-deployment validations as bureaucratic drag.
But here’s the truth:
Speed without safety is just gambling.
If your process lets anything through, then every deployment is a roll of the dice. You might ship fast for a week, a month, maybe more. But the day you land on snake eyes, you’ll pay for every shortcut you took.
What We Learned (the Hard Way)
After that incident, the team didn’t give up on speed. They just got smarter about protecting it.
They implemented a lightweight set of automated quality gates:
Code coverage minimums in the CI pipeline
Linting enforcement to catch common errors
Pre-deployment integration tests for critical flows
Canary releases with health monitoring
They didn’t add red tape. They added resilience.
The result? Rollback incidents dropped by 70%. Developers kept shipping daily, but now with a net under the high wire.
Velocity didn’t slow down. Fear did.
The Tool: Quality Gates in CI/CD
If you want sustainable speed, you need confidence. And confidence comes from knowing that what you ship won’t explode at runtime.
That’s what quality gates are for:
Linting: Enforce basic hygiene before code gets merged.
Test coverage thresholds: Ensure your tests aren’t just an afterthought.
Static analysis: Catch complexity, potential bugs, and anti-patterns early.
Integration test suites: Prove the whole system still works.
Deployment safety checks: Validate infra before rolling out.
These aren’t blockers. They’re bodyguards for your speed.
Yes, they take time to set up. Yes, they sometimes delay a bad commit from shipping.
But that’s the point.
A quality gate that blocks a bug before it hits production just bought you hours (or days) of recovery time you never had to spend.
Final Thought
Skipping quality gates to ship faster is like removing your car’s brakes to save weight.
Sure, you might hit top speed quicker — until the first sharp turn.
Velocity isn’t about how fast you can go. It’s about how fast you can go safely.
Build that into your pipelines, and speed becomes sustainable. Ignore it, and you’re not scaling — you’re setting a timer on your next incident.
The Quality Illusion: Why Testing Can’t Save Your Product
(And Why You Should Stop Trying to Fix Quality at the Finish Line)
Let’s start with an uncomfortable truth: You can’t test the quality into a product. You just can’t. It’s like trying to build a house by slapping on fresh paint at the last moment, hoping no one notices the foundation is made of matchsticks.
Yet, organizations continue to pour millions into testing, inspection, and post-production quality control as if these activities will somehow transmute a flawed product into a perfect one. Spoiler alert: They won’t. At best, testing identifies defects. At worst, it gives a false sense of security while burning time and money.
The real answer? Build quality in from the start. Not as an afterthought, not as a secondary process, but as an intrinsic part of design, development, and production.
The Great Quality Control Myth
Let’s debunk a common industry delusion: the more you test, the higher your quality. That’s like saying the more times you check your car’s gas gauge, the more fuel-efficient your vehicle becomes. Testing is an indicator, not a solution.
W. Edwards Deming, the godfather of modern quality management, put it bluntly: “Inspection does not improve the quality, nor guarantee quality. Inspection is too late. The quality, good or bad, is already in the product.”
Toyota figured this out decades ago. Instead of relying on armies of inspectors to catch defects, they built quality into the process. Their philosophy—Jidoka (automation with a human touch)—means the system itself detects and prevents errors before they ever become defects.
Why Testing as a Safety Net Fails
Imagine you’re coaching a ski team. Would you rather train athletes to navigate the course flawlessly, or just have paramedics at every turn, ready to deal with their inevitable wipeouts? Most businesses choose the latter. They rely on testing to catch failures rather than designing processes that prevent them.
Here’s where testing falls apart:
It’s Too Late – If defects are discovered in testing, that means defective units were already made. The cost of fixing a problem increases exponentially the later it’s found. Juran’s “Cost of Poor Quality” model shows that fixing defects in production costs 10x more than fixing them in development, and up to 100x more once the product is in the customer’s hands.
It’s Inconsistent – Even with rigorous testing, some defects will slip through. Sampling isn’t foolproof. If your defect rate is 0.1% and you ship a million units, congratulations, you’ve just sent 1,000 defective products to customers.
It Creates a Blame Culture – Testing-centric approaches lead to “over-the-wall” thinking. Designers blame engineers, engineers blame manufacturing, and manufacturing blames testing. Nobody takes ownership of quality because, well, “That’s QA’s problem.”
Building Quality In: Where It Actually Starts
So, if testing isn’t the answer, what is? Quality by design. The world’s best manufacturers—from Toyota to Apple—have figured this out. They follow a few key principles:
1. Zero Defects is a Design Principle, Not a Fantasy
Philip Crosby’s Quality is Free made an argument that still rattles some executives today: it’s cheaper to build quality in than to fix defects later. His Zero Defects concept isn’t about perfectionism—it’s about eliminating errors at the source.
Case in point: Shigeo Shingo’s Poka-Yoke (mistake-proofing) system at Toyota. Instead of relying on workers to avoid errors, the system itself prevents mistakes from happening in the first place. Think of the sensors in your car that stop you from driving away with your fuel cap open. That’s Poka-Yoke.
2. Prevention Trumps Inspection
The best quality control? One that makes defects impossible. Look at Six Sigma, which aims for just 3.4 defects per million opportunities. But that level of excellence only happens when defect prevention is embedded into every process, not just caught at the end.
In software development, this means shifting left—finding and fixing defects in the design phase rather than in testing. In manufacturing, it means adopting Lean principles to build error-proof processes from the start.
3. Cross-Functional Quality Ownership
Quality isn’t the job of a single department. It belongs to everyone. Toyota’s Quality Circles bring together frontline workers, engineers, and managers to improve processes proactively.
At Amazon, every software engineer is responsible for the quality of their own code—there’s no separate QA department to clean up their mess.
Who Actually Benefits from Late-Stage Testing?
The biggest irony? The obsession with testing doesn’t actually benefit end-users. It benefits executives who want easy metrics.
A massive testing operation creates the illusion of control.
High defect detection rates look impressive on reports.
Delays caused by quality issues can be spun into narratives about “rigorous standards.”
But customers don’t care about how many defects you found—they care about how many you delivered.
The Blueprint for Real Quality
So, what does building quality in actually look like in digital product management?
Management:Quality must be a strategic goal, not an operational afterthought.
Innovation: Invest in better processes, not just better tests.
Experience: User feedback should drive design, preventing usability defects before they exist.
Quality: Focus on prevention, not detection.
Engineering: Automate quality controls within the process itself.
Architecture: Design systems for resilience, not just for compliance.
The Closing Thought: Quality is a Bridge, Not a Fence
If testing is a safety net, then designing for quality is a bridge—a well-engineered, reliable structure that doesn’t need a net because failure isn’t an option.
So, next time someone argues that more testing is the answer, remind them: skiers don’t become champions by falling less. They win by skiing better.
A few years ago, I worked with a growing software company that struggled to deliver features on time. Deadlines were slipping, and teams were frustrated.
When I asked developers what was causing the delays, they pointed to endless bug fixes that took precedence over new features.
One senior developer told me, “We know where the bugs come from, but it’s impossible to stop them—tight timelines don’t allow us to focus on quality up front.”
This reminded me of Shigeo Shingo’s timeless wisdom:
“It’s the easiest thing in the world to argue logically that something is impossible. Much more difficult is to ask how something might be accomplished.”
Everyone can come up with a thousand reasons why something won’t work. But the question we should ask instead would be: “What needs to happen to make it work?”
Shingo’s principles are as relevant to software development as they are to manufacturing. Instead of accepting problems as inevitable, he challenged teams to rethink their processes and eliminate issues at the source.
Applying this mindset to the software team, we implemented automated testing and continuous integration (CI).
While it required initial effort, these changes reduced bugs significantly by catching issues earlier in development.
Teams were empowered to focus on building new features, and morale improved as they delivered higher-quality software on time.
Ask “How Might We?”: When faced with recurring issues, ask your team to brainstorm ways to solve them permanently, even if the solution initially seems challenging.
Adopt Automation: Automate tasks prone to human error, like testing or code reviews, to catch defects early and streamline workflows.
Build Quality into the Process: Use practices like pair programming, code linting, or CI/CD pipelines to ensure problems are addressed as they arise, not after release.
The takeaway? Stop accepting “impossible” as the answer.
With the right mindset and tools, you can transform recurring issues into opportunities for innovation.
Have you ever turned an “impossible” challenge into a win? If so, share your story with me—I’d love to hear it!
Recently, I traveled via Cologne’s central train station. I forgot to calculate that November 11 is a special day in Cologne. And whether you like carnival or not, it will be memorable. I had to catch my connection train, but everything was different this November 11 evening.
Thousands of people were in this train station, and almost everyone was in a costume. Squeezed between hundreds of people on a platform, waiting for a train, it felt like I was the only sober person there. This is what chaos must feel like. So many people laugh, argue, fight, sing, hug, celebrate, and have fun. There was a band about 10m away on the platform, tirelessly performing in the middle of the crowd. Right next to me was a person sleeping on the ground dressed like a bee. Right next to this sleeping bee, a puking princess and a pirate arguing with heavy gestures with Robin Hood. And people everywhere. I wasn’t aware that so many people could fit on a single train platform; bizarre and impressive at the same time.
The situation became even more traumatic when the announcement was made that the train would arrive at a different platform. Then, the entire crowd got active and moved. But there was no real space to move, but somehow, everyone found their way nonetheless, running, pushing, cursing.
Most of the trains had been delayed since the trains had been heavily overloaded, and drunk people tried to squeeze in or hold the door open for a friend. The trains had been so packed you could not move nor fall in any direction. This is how a fish in a can might feel if still alive. On the plus side, you meet many people and get involved in funny conversations. Here and there, an elbow in your stomach if the person next to you tries to move. This was socializing at its best. I made many new friends, even if I will not meet those people again or might even recognize them without a costume. Interestingly, it was horrible and annoying and fun at the same time.
However, from a quality management perspective, the train station management was prepared for this event. Security guards were on the stairs and the platforms and at the most critical bottleneck points. At first, I thought those yellow high-visibility vests were just a common workaround if you forgot your costume, but those people had been placed there for a reason. They tried to regulate and control the constant flow of drunk people. They stopped people from entering an already overcrowded platform. They tried to get the train doors free from people so that they could close. They ensured nobody was too close to the platform’s edge when a train arrived or departed.
This means there was a process in place for precisely this kind of event. And that’s good! The process had been initiated, and the security guards appeared in the right places. But now, it was observable that those guards did their jobs differently. Some ran around screaming angrily, yelling at people if they didn’t follow their instructions. Others had difficulty getting heard, and it appeared they had given up and just stood there. Again, others did their best but didn’t find a way to influence the crowd. As a result, the customer experience went down. Consider the people on the platforms to be railway customers. Nobody likes to be yelled at or treated without respect, not even the Prince of Persia or Bumble Bee, nor that nun with the strange face tattoo. Other security guards acted in an assertive but understanding, friendly, humorous, and funny way. But probably not because they had been told so, but because it was their way of doing things anyway.
What does this mean? There was a process in place, but it probably wasn’t detailed or precise enough so that the players in that process knew how to execute it. In addition, they were not enabled to perform the process either. It appeared like: “Here is a yellow vest. Show up at this place and ensure nobody gets hurt or delays a train.” But how to do that wasn’t specified, nor were the people enabled to define the ‘how’ themselves.
As a result, the process didn’t work as expected. It failed in significant parts. Sometimes, good intentions, a good start, and a good idea aren’t enough if the implementation has flaws and fails.
And isn’t that the case in many companies? There are processes in place, but people either are unaware of them, essential pieces are missing, people are not enabled or empowered, or the organization is not mature enough to execute the processes. The good intentions got halfway stuck here.
Hence, if you do quality, do it right. There is no half-assing when it comes to quality.
Early in my career as a quality manager, I was part of a team tasked with overhauling a software company’s quality assurance processes. We crafted a robust strategy, implemented cutting-edge systems, and restructured departments for optimal efficiency.
On paper, everything was flawless. Yet, months later, quality issues persisted. Curious about the disconnect, I walked the floor, asked questions, talked to people, listened, and noticed that employees were still clinging to their old methods and were resistant to the new processes we introduced.
This experience taught me a crucial lesson: even the best strategies and systems fail if they don’t consider the human element.
As John Kotter wisely said, “The central issue is never strategy, structure, culture, or systems. The core of the matter is always about changing people’s behavior.”
Real transformation happens when we focus on helping individuals understand, embrace, and commit to new ways of working.
This reminds us that at the heart of every organizational change are people whose behaviors determine success or failure.
Hence, please don’t underestimate the power of change management – or the danger of not considering it.
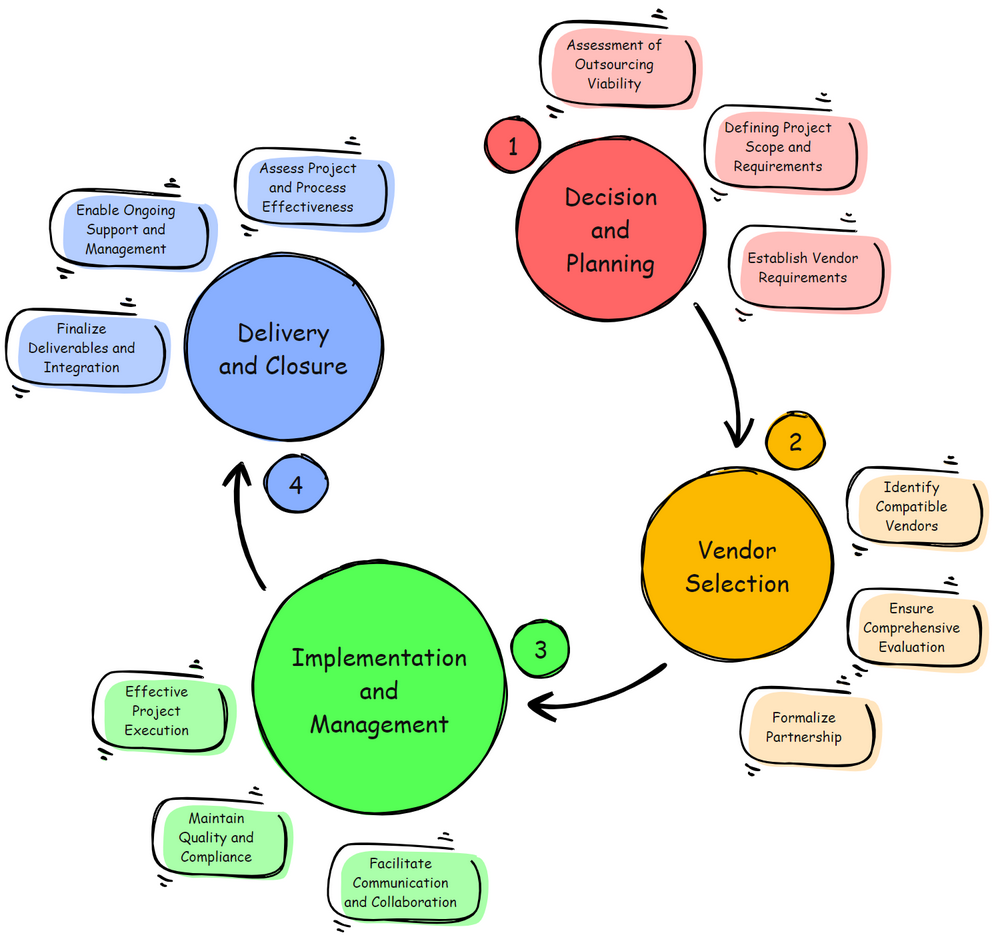
Many companies consider software outsourcing a strategic decision to leverage specialized skills, reduce costs, or improve efficiency. However, outsourcing can fail to meet its objectives without a structured approach. Drawing from extensive experience as a Quality Manager, here is a robust four-phase process to ensure outsourcing success.
Most companies neglect the first 2 phases, struggle then in phase 3, and the project fails heroically in phase 4. Hence, consider putting some effort into the first two phases to have smoother phases 3 and 4 and, most importantly, a successful outsourcing project closure.
Phase 1: Decision and Planning
The initial phase focuses on evaluating whether outsourcing is suitable for your project at all. This involves an in-depth assessment of the business needs and potential benefits versus the risks. Companies must also define the project’s scope and requirements clearly. This clarity ensures potential vendors understand what is expected of them, reducing miscommunications and project scope creep.
Key actions include:
Assess outsourcing viability by examining the alignment with business goals and the cost-effectiveness of outsourcing versus in-house development.
Define project scope and requirements to specify project objectives, deliverables, technical needs, and success metrics.
Establish vendor requirements to ensure potential partners have technical expertise, compliance standards, and communication capabilities.
Phase 2: Vendor Selection
Choosing the right vendor is critical. This phase involves identifying vendors with technical capabilities that align with your company’s business ethics and cultural values.
Steps to ensure effective vendor selection:
Identify compatible vendors through rigorous evaluation of their technical and cultural alignment with your project needs.
Ensure a comprehensive evaluation by using detailed Requests for Proposals (RFPs) and structured interviews to assess potential vendors’ capabilities and proposals.
Formalize partnership by negotiating and signing contracts clearly defining roles, responsibilities, scope, and expectations.
Phase 3: Implementation and Management
With the vendor selected, the focus shifts to project execution. Effective management ensures the project remains on track and meets all defined objectives.
Critical management tasks include:
Effective project execution to oversee the project from start to finish, ensuring adherence to the project plan and achievement of milestones.
Maintain quality and compliance through regular quality checks and adherence to industry standards.
Facilitate communication and collaboration to ensure all stakeholders are aligned, which helps address issues promptly and adjust project scopes as needed.
Phase 4: Delivery and Closure
The final phase involves integrating and closing out the project. Ensuring that the deliverables meet quality standards and are well integrated into existing systems is paramount.
Key closure activities:
Finalize deliverables and integration to ensure all software meets quality standards and integrates smoothly with existing systems.
Enable ongoing support and management by training internal teams to manage and maintain the software effectively.
Assess project and process effectiveness through a post-implementation review to identify successes, lessons learned, and areas for improvement.
Conclusion
Effective outsourcing is not just about choosing a vendor and signing a contract; it’s a comprehensive process that requires careful planning, execution, management, and closure. By adhering to these four structured phases, companies can enhance their chances of outsourcing success, leading to sustainable benefits and growth. This approach not only helps in achieving the desired outcomes but also in building strong, productive relationships with outsourcing partners.
A Business Impact Analysis (BIA) is a systematic process that organizations undertake as part of their Business Continuity Planning (BCP) and Business Continuity Management (BCM) efforts. It is a crucial phase that lays the foundation for developing robust and effective strategies to mitigate the impacts of potential disruptions on critical business operations.
Clarity on the objectives of a BIA is essential for ensuring a comprehensive and focused analysis. Organizations can gather valuable insights and make informed decisions to safeguard their operations and maintain business continuity by aligning the process with well-defined objectives.
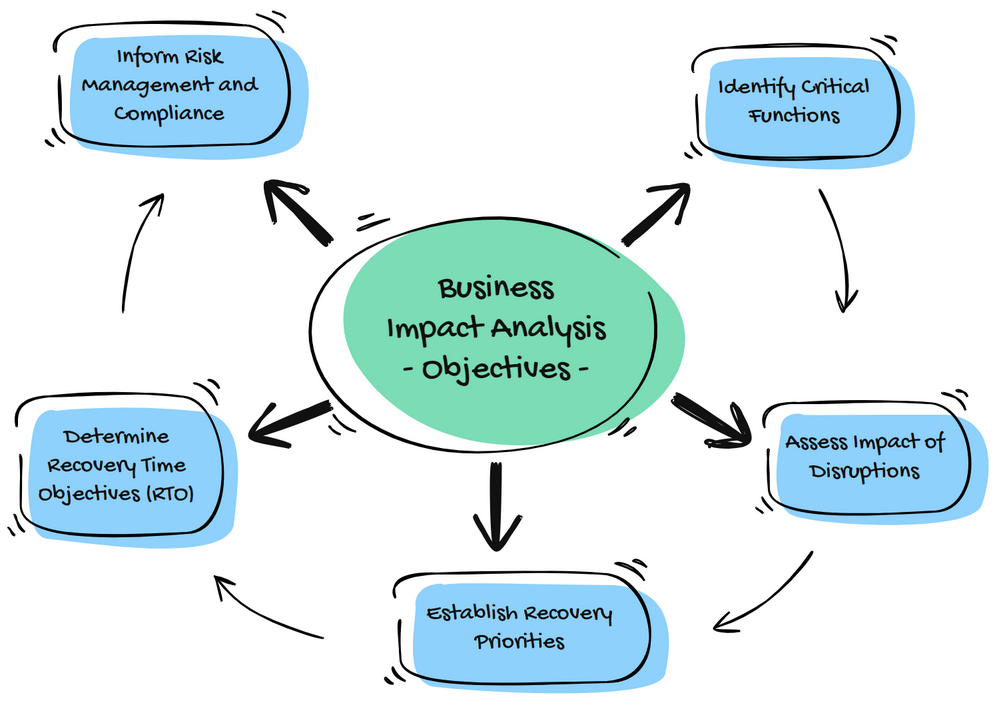
Here are some key objectives that should guide the BIA process:
Identify Critical Functions: The primary objective of a BIA is to identify the critical functions and processes that are vital to the organization’s survival and continued operation. The organization can prioritize recovery efforts during disruptions by pinpointing these essential functions and ensuring that resources are allocated effectively.
Assess Impact of Disruptions: A BIA aims to quantify potential disruptions’ operational and financial impacts on the identified critical functions. This assessment helps organizations understand the risks associated with business continuity and the possible consequences of inadequate recovery strategies.
Establish Recovery Priorities: The BIA enables organizations to prioritize recovery efforts based on criticality and impact assessments. Organizations can allocate resources efficiently during a crisis by understanding which functions require immediate attention and which can be addressed later, minimizing downtime and potential losses.
Determine Recovery Time Objectives (RTO): The BIA process helps define acceptable downtime or Recovery Time Objectives (RTO) for each critical function. These RTOs guide the development of recovery plans and inform the investments required to achieve the desired level of resilience.
Inform Risk Management and Compliance: The insights gained from the BIA feed into the broader risk management process and compliance requirements. By providing detailed information on potential vulnerabilities and regulatory obligations, the BIA supports organizations in developing comprehensive risk mitigation strategies and ensuring compliance with relevant industry standards and regulations.
A well-executed BIA ensures that organizations can respond promptly and effectively to disruptions, maintaining operational integrity and stakeholder confidence by clearly defining and aligning with these objectives. It serves as a critical foundation for building resilience and minimizing the impact of unforeseen events on business continuity.
When it comes to Business Continuity planning, many companies tend to disregard its importance. They might argue, “We haven’t needed it in 20 years; it’s not worth the paper; it’s a waste of time and resources.” At first glance, Business Continuity planning seems comparable to paying for liability or flood insurance — like pouring money into something you hope never to use. This perspective can make one question the rationale behind such preparations. Yet, just as with insurance, having a Business Continuity plan in place in the event of an unforeseen disaster becomes invaluable.
But what is Business Continuity?
So, let’s define Business Continuity:
“Business continuity refers to an organization’s advanced planning and preparation to ensure that it can continue its critical business functions during and after significant disruptive events.”
This involves identifying vital systems and processes and implementing strategies to minimize disruption and recovery time.
Business continuity aims to maintain essential operational functions and recover quickly from disruptions, such as natural disasters, technological problems, or other unforeseen circumstances.
This ensures the organization can continue to deliver its services or products at acceptable predefined levels, even during a crisis.
In short, Business Continuity is a company’s ability to efficiently deal with crises and survive events that, if left unhandled, could destroy entire businesses.
Examples are a longer power or Internet outage, natural disasters like earthquakes or floods, or a fire in your basement data center. All those events can potentially kick you out of business for a while or, in the worst case, forever.
There are two parts of Business Continuity.
Two terms are often mixed up regarding business continuity: BCM and BCP.
But there is a difference between both, and here is which:
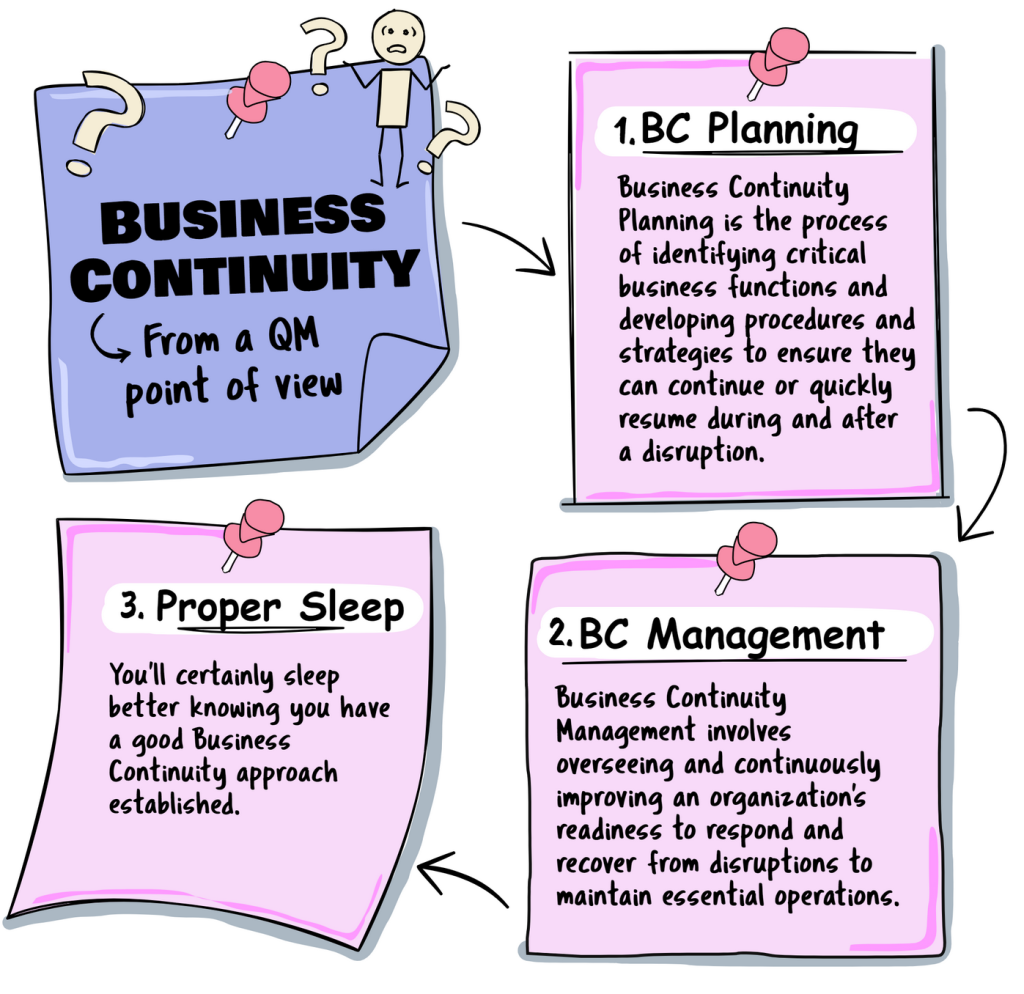
Business Continuity Planning (BCP): This refers specifically to the process involved in creating a system of prevention and recovery from potential threats to a company. The plan ensures that personnel and assets are protected and can function quickly in a disaster. BCP is essentially creating a strategy by recognizing threats and risks facing a company, intending to ensure that personnel and assets are protected and able to function in the event of a disaster.
Business Continuity Management (BCM): This is a broader approach that includes managing the overall business continuity program. BCM encompasses not only the development and maintenance of plans like BCP but also the ongoing management, assessment, and improvement of these plans. It involves integrating business continuity into the organization’s day-to-day operations and culture. It is more comprehensive and includes all aspects of organizational resilience.
And what now?
It depends. If you are ready to bridge a couple of months after a disaster or other company-threatening event, then you don’t need to bother with Business Continuity.
But if a few weeks or even a few days of missing revenue will hurt your business or even throw you off track, you should certainly consider business continuity.
Feel free to contact me if you need help with that.
Embarking on the Journey: The Critical Role of DoD in Agile Projects
With its rapid developments and impressive results, Navigating the world of Agile demands one essential element for success: clear definitions. That’s where the Definition of Done (DoD) comes into play.
Imagine a scenario: a team is tasked with building a car. The specifications are clear, but what does ‘done’ really mean?
For the engineer, ‘done’ might mean the engine runs smoothly. For the designer, it’s about the final polish and aesthetics. For the quality inspector, ‘done’ is not reached until every safety test is passed with flying colors.
Here lies the essence of the DoD dilemma – without a universally accepted definition of ‘done,’ the car might leave the production line with a roaring engine and a stunning design but lacking critical safety features.
In Agile projects, this is a common pitfall. Teams often have varied interpretations of completion, leading to inconsistent and sometimes incomplete results.
A meticulously constructed DoD serves as the critical point of convergence for different team viewpoints, guaranteeing that a task is only considered ‘done’ when it fully satisfies every requirement – encompassing its functionality and aesthetic appeal, safety standards, and overall quality.
Let’s explore how the DoD transforms Agile projects from a collection of individual efforts into a cohesive, high-quality masterpiece.
From Chaos to Clarity: A Real-World Story of Transformation
Let me take you back to a time in my career that perfectly encapsulates the chaos resulting from a lack of a universally understood DoD. In a former company, our project landscape resembled a bustling bazaar – vibrant but chaotic.
Both internal and external teams were diligently working on a complex product, each with their own understanding of ‘completion.’
The first sign of trouble was subtle – code contributions from different teams that didn’t fit together smoothly. A feature ‘completed’ by one team would often break the functionality of another. The build failures became frequent, and the debugging sessions became prolonged detective hunts, frequently ending in finger-pointing.
I recall one incident vividly. A feature was marked ‘done’ and passed on for integration. It looked polished on the surface – the code was clean and functioned as intended. However, during integration testing, it failed spectacularly.
The reason? It wasn’t compatible with the existing system architecture. The team that developed it had a different interpretation of ‘done.’ For them, ‘done’ meant working in isolation, not as a part of the larger system. Hence, we had to rework everything, throwing away weeks of work.
This experience was our wake-up call. It made us realize that without a shared, clear, and comprehensive DoD, we were essentially rowing in different directions, hoping to reach the same destination. It wasn’t just about completing tasks but about integrating them into a cohesive, functioning whole.
This realization was the first step towards our transformation – from chaos to clarity.
Unveiling the DoD: Components of a Robust Agile Framework
After witnessing firsthand the chaos that ensues without a clear DoD, let’s unpack what a robust Definition of Done should encompass in an Agile project.
But let’s start with a definition.
What is a Definition of Done (DoD)?
The Definition of Done (DoD) is an agreed-upon set of criteria in Agile and software development that specifies what it means for a task, user story, or project feature to be considered complete.
The development team and other relevant stakeholders, such as product owners and quality assurance professionals, collaboratively establish this definition.
The DoD typically encompasses various deliverable aspects, including coding, testing (unit, integration, system, and user acceptance tests), documentation, and adherence to coding standards and best practices.
By clearly defining what “done” means, the DoD provides a clear benchmark for completion, ensuring that everyone involved in the development process has a shared understanding of what is expected for a deliverable to be considered finished.
Now we know what a DoD is. But I’d like to elaborate once more on why it is needed:
Why is the Definition of Done Necessary?
The DoD is essential for several reasons.
Firstly, it ensures consistency and quality across the product development lifecycle. By having a standardized set of criteria, the development team can uniformly assess the completion of tasks, thus maintaining a high-quality standard across the project.
Secondly, it facilitates better collaboration and communication between the teams and with stakeholders. When everyone agrees on what “done” means, it reduces ambiguities and misunderstandings, leading to more efficient and effective collaboration.
Thirdly, the DoD helps in effective project tracking and management. It provides a clear framework for assessing progress and identifying any gaps or areas needing additional attention.
Finally, it contributes to customer satisfaction; a well-defined DoD ensures that the final product meets the client’s expectations and requirements, as every aspect of the product development has been rigorously checked and validated against the agreed-upon criteria.
Right, but what does such a DoD look like?
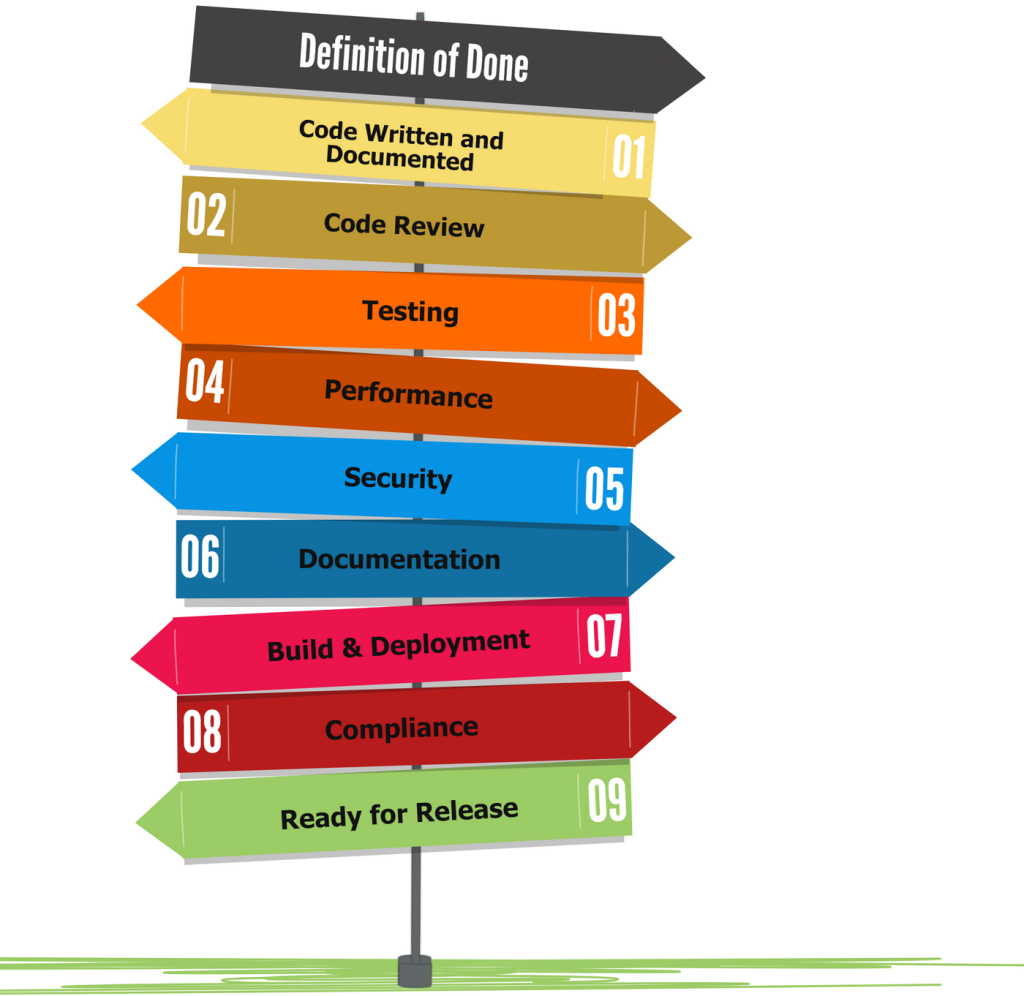
Understanding the key components of a Definition of Done (DoD) is crucial for a successful Agile project. Here are some typical elements that can be included in a DoD. Remember, these are illustrative; depending on your team’s consensus and project requirements, your DoD may have more, fewer, or different points.
Code Written and Documented: Not only should the code be fully written and functional, but it should also be well-documented for future reference. For instance, a user story isn’t done until the code comments and API documentation are completed.
Code Review: The code should undergo a thorough review by peers to ensure quality and adherence to standards. A user story can not be marked done when it has not been reviewed and approved by at least two other team members.
Testing: This includes various levels of testing – unit, integration, system, and user acceptance tests. A feature is done when all associated tests are written and passed successfully, ensuring the functionality works as expected.
Performance: The feature must meet performance benchmarks. This means that it functions correctly and does so within the desired performance parameters, like load times or response times.
Security: Security testing is critical. A feature can be considered done when it has passed all security audits and vulnerability assessments, ensuring the code is secure from potential threats.
Documentation: Apart from code documentation, this includes user and technical documentation. A task is complete when all necessary documentation is clear, comprehensive, and uploaded to the relevant repository.
Build and Deployment: The feature should successfully integrate into the existing build and be deployed without issues. For instance, a feature is done when it’s deployed to a staging environment and passes all integration checks.
Compliance: Ensuring the feature meets all relevant regulatory and compliance requirements. For example, a data processing feature might only be considered done after verifying GDPR compliance.
Ready for Release: Lastly, the feature is not truly done until it’s in a releasable state. This means it’s fully integrated, tested, documented, and can be deployed to production without any further work.
The last point is probably the most important since it indirectly includes all other points. The feature should be “potentially releasable”. This means it would be ready to be released at any time. And this, of course, can only be answered with yes if the points before are considered.
While these are common elements in many DoDs, it’s important for teams, especially in projects with multiple teams or external stakeholders, to agree on these points to ensure consistency and quality across the board. A well-defined DoD is a living document, subject to refinement and evolution as the project progresses and as teams learn and adapt.
Your Roadmap to Agile Excellence: Implementing DoD Effectively
Having understood the pivotal role of DoD and its components, the next step is its effective implementation. This is where theory meets practice and where true Agile excellence begins. Let’s explore the roadmap to integrate DoD into your Agile projects effectively.
Collaborative Creation: The DoD should be a collaborative effort, not a top-down mandate. Involve all relevant stakeholders – developers, QA professionals, product owners, and, if possible, even customers. This collaborative approach ensures buy-in and shared understanding across the team.
Customization is Key: There is no one-size-fits-all DoD. Each project is unique, and your DoD should reflect that. Consider your project’s specific needs and goals when defining your DoD criteria.
Keep it Clear and Concise: A DoD overloaded with too many criteria can be as ineffective as having none. Keep your DoD clear, concise, and focused on what truly matters for the project’s success.
Regular Reviews and Updates: Agile is all about adaptability. Regularly review and update your DoD to reflect changes in project scope, technology advancements, or team dynamics. This ensures that your DoD remains relevant and effective throughout the project lifecycle.
Visibility and Accessibility: Ensure the DoD is visible and accessible to all team members. Whether on a physical board in the office or a digital tool accessible remotely, having the DoD in plain sight keeps everyone aligned and focused.
Conclusion: Implementing a clear and comprehensive DoD is a game-changer in Agile project management. It transforms ambiguity into clarity, aligns team efforts, and significantly enhances the quality of the final deliverable. If you want to elevate your Agile projects, start by refining your DoD.
And remember, if you need more personalized guidance or assistance in creating an effective DoD for your team, I’m here to help. Let’s connect and turn your Agile projects into success stories.
Embarking on the Journey of Quality Management with Test Cases
Quality Management (QM) is a crucial aspect of any successful business, but for beginners, the labyrinth of its concepts can be daunting. One fundamental pillar in this realm is the ‘Test Case.’ A test case is more than just a procedure; it’s the blueprint for ensuring your product or service meets its designed quality. But why are test cases so vital? Let’s dive into the world of test cases and unravel their importance in maintaining and enhancing the quality of your projects.
A Personal Tale: The Chaos of Ignoring Documented Test Cases
Navigating the world of quality assurance without a map can be a harrowing experience, as I learned in a company that lacked documented test cases. Initially, the existing QA team, seasoned and skilled, seemed to manage well, relying on their memory and experience, until it didn’t. The cracks in this approach became glaringly evident when we faced two critical situations.
First, the sudden departure of a seasoned QA engineer left us in disarray. This individual, a repository of unwritten knowledge, had carried out complex tests effortlessly, but without documentation, his departure created a vacuum. We scrambled to reconstruct his methods, facing delays and quality issues – a stark reminder of the fragility of relying on implicit knowledge.
The second challenge arose with the arrival of a new QA engineer. Eager but inexperienced, she struggled immensely to grasp the nuances of our testing procedures. The absence of clear, documented test cases meant she had to rely on piecemeal information and constant guidance from overburdened colleagues. This slowed her integration into the team and highlighted the inefficiencies and risks of not having structured, accessible test case documentation.
These experiences taught me a critical lesson: the indispensable role of well-documented test cases in preserving organizational knowledge and facilitating new team members’ smooth onboarding and growth in Quality Management.
Breaking Down Test Cases: The Essential Components Explained
So, what exactly is a test case? In simple words:
A test case is a set of actions executed to verify your product or service’s particular feature or functionality.
Of course, there is more to it, e.g., the entire topic of test automation or special test cases like performance or security tests. But let’s go with this simple definition of a test case for now.
Understanding the anatomy of a test case is crucial for anyone beginning their journey in Quality Management. A well-crafted test case is a blueprint for validating the functionality and performance of your product or service. Let’s dissect the essential components of a good test case:
ID (Identification): Each test case should have a unique identifier. This makes referencing, tracking, and organizing test cases more manageable. Think of it as a quick way to pinpoint specific tests in a large suite. This way, renaming a test case won’t blow your test plans or entire setups since the ID will stay the same.
Description: This briefly overviews what the test case aims to verify. A clear description sets the stage by outlining the purpose and scope of the test, ensuring everyone understands its intent. This description should be written in a way that can be easily understood, even by new colleagues.
Pre-conditions: These are the specific conditions that must be met before the test is executed. This can include certain system states, configurations, or data setups. Pre-conditions ensure that the test environment is primed for accurate testing.
Steps: This section outlines the specific actions to be taken to execute the test. Each step should be clear and concise, guiding the tester through the process without ambiguity. Well-documented steps prevent misinterpretation and ensure consistent execution.
Test Data: This includes any specific data or inputs required for the test. Providing detailed test data ensures that tests are not only repeatable but also that they accurately mimic real-world scenarios.
Expected Results: What should happen as a result of executing the test? This section details the anticipated outcome, providing a clear benchmark against which to compare the actual test results. The expected results are often listed for each test case step.
Status: Post-execution, the status indicates whether the test has passed or failed. It’s a quick indicator of the health of the feature or functionality being tested.
Each component plays a pivotal role in crafting a test case that is not just a document but a tool for quality assurance. They collectively ensure that each test case is repeatable, reliable, and effective in catching issues before they affect your users.
By understanding and implementing these components in your test cases, you lay a strong foundation for a robust Quality Management system, one that is equipped to maintain high standards and adapt to changing requirements.
Revamping Your Test Case Strategy: A Call to Action for Beginners
As a beginner in Quality Management, you might wonder, “Where do I start?” The first step is to review or establish your test case documentation strategy. Ensure your test cases are simple yet detailed enough to cover all necessary aspects. Regular reviews and updates to these documents are vital. Remember, a test case is not a static document; it evolves with your product. By systematically documenting test cases, you safeguard your product’s quality and build a resilient framework that can withstand personnel changes and scale with your project’s growth.
Conclusion
The journey to mastering test cases in Quality Management is ongoing. It’s time to rethink your approach if you haven’t taken test case documentation seriously. Implementing robust test case practices enhances your product’s quality and fortifies your team’s efficiency and adaptability. Embrace this change and take the first step towards quality excellence. Your future self will thank you.
The Decision Quandary: Entering the Maze of Choices
Every day, we face numerous decisions. Some are trivial, like choosing what to wear, while others significantly affect our personal and professional lives. But what happens when the options are so close that deciding becomes a dilemma? In these moments, the weight of “Decisions” can feel overwhelming, leading to indecision and lost opportunities. This post explores effective strategies to navigate these challenging decision-making scenarios.
My Battle with Decision Paralysis: A Personal Journey
Reflecting on my own life, I realize that if I had summed up the hours spent pondering over close decisions, I could have instead enjoyed a relaxing beach vacation or an exhilarating mountain climb. And not only that. Often, the overthinking led to missed opportunities, as the choices slipped away while I was lost in thought. This personal struggle with decision paralysis is not unique. It’s a common challenge that many of us face, especially in our professional lives, where the stakes are high and the choices are not clear-cut.
Deciphering the Decision Code: 4 Simple Key Strategies
The Equivalence Rule: When options are neck and neck, the impact of your choice is likely minimal. In Quality Management, consider a scenario where you choose between two equally reputable suppliers. Both offer similar quality materials at comparable prices. In such cases, understand that either choice will likely yield similar outcomes. The key is not to overburden yourself with over-analysis when the options are closely matched. So simply choose one. Done.
The Coin Toss Insight: This method is less about leaving the decision to chance and more about uncovering your true preference. Imagine you’re deciding between two quality control processes: Method A, which is familiar but time-consuming, and Method B, which is innovative but untested.
During-Toss Emotion Check: As the coin spins in the air, you find yourself hoping it lands in favor of Method B. This reaction is a powerful indicator of your genuine preference, often hidden under layers of analytical thinking. In this case, ignore the coin and go for option B.
Post-Toss Emotion Check: If, upon the coin landing, you feel a sense of relief or disappointment, it’s a signal. For instance, if the coin dictates Method A, but you feel a twinge of disappointment, it’s a sign that you’re more inclined towards Method B. In this case, ignore the coin and trust this emotional response; it often holds more wisdom than we credit it for.
Simplicity as a Strategy: In complex decision-making scenarios, opting for simplicity can be a surprisingly effective approach. For instance, when choosing between implementing a complex new software or making incremental improvements to an existing system, the simpler solution might be the latter. It avoids the potential risks and learning curve associated with new software, especially when the benefits of both options are similar.
Delegating Decisions: This approach is particularly useful in collaborative environments. For example, if your team is equally split between adopting a new quality inspection tool or sticking with the current method, delegating the decision to the team can be empowering. It not only fosters team responsibility and engagement but also leverages the group’s collective expertise.
Turning Decisions into Action: Your Next Steps
The journey from indecision to action requires not just understanding these strategies but also applying them. Start by acknowledging that not every decision warrants extensive deliberation. Trust in the simpler options, use the coin toss as a tool to uncover your true preferences, listen to your emotional cues, and don’t shy away from delegating decisions when appropriate. Remember, in close calls, the act of deciding is often more important than the decision itself.
“Decisions” are an integral part of our lives. By applying these four strategies, you can navigate through close and uncertain choices with more confidence and less stress. Remember, the goal is not to avoid wrong decisions but to make decisions effectively and efficiently. Now, it’s your turn to put these strategies into practice and transform the way you make decisions.
Engaging Prelude: First Steps into Chaos – The Crucial Awakening
Envision a majestic ship representing a thriving organization sailing into the unpredictable seas of the corporate world. Each crew member, vibrant and brimming with potential, is eager to contribute to the journey ahead. However, without a guiding compass — Policies —the ship is left vulnerable to the capricious tides, risking deviation from its intended course.
The lack of well-established policies or inadequate communication thereof is akin to a ship sailing blindfolded, a precursor to disorder and potential downfall. These guiding principles are the bedrock of any organization, ensuring a steadfast journey through calm and tumultuous times, ultimately leading toward success and stability.
This exploration delves into the transformative power of well-implemented policies and their essential role in sculpting an organization’s destiny. Let’s embark on this enlightening journey, uncovering the significance of organizational policies, the chaos in their absence, and the pathway to a stable and prosperous future.
Chronicles of Chaos: A Tale of Turmoil – The Ripple Effect of Missing Policies
Once upon a time, there was a mix of excitement and dreams in a lively and growing company. But, like a ship sailing on the sea without a map, this company didn’t have enough rules to guide its journey. The employees were like sailors, trying their best to navigate, but they sometimes got lost without clear directions.
One day, chaos snuck in through a small mistake. Not knowing the rules about what could be shared, an employee tweeted something that should have stayed inside the company. This small action created big waves, like a storm in the sea, affecting everyone in the company. There was a rush to fix the problems, a storm that could have been avoided if there was a clear rule about using social media.
This isn’t just a single story. It’s like many tales of ships and sailors trying to find their way on the big sea without a map or compass. When there aren’t clear rules, or the sailors don’t know them, it’s easy to make mistakes and get into trouble.
Understanding and Managing Policies in a Company
Let’s start with the definition of a policy. What is a policy?
In the context of a business, a policy is a set of principles or rules that guide decision-making and behavior within the organization. These guidelines help maintain a consistent and organized approach, ensuring all employees are on the same page and working towards common goals.
Handling and Management of Policies
Effective policy handling and management require awareness, accessibility, clarity, approval by higher management, regular reviews, and designated ownership. Addressing the following questions can help ensure that policies are appropriately managed:
Is every employee aware of your policies?
Does every employee know where to find your policies? Are they all stored or linked from a single, accessible place?
Are your policies recognizable as such? Is the term “Policy” clearly indicated, perhaps on the cover page?
Are your policies approved or signed by higher management? Is it clear who approved them, in what role, and when?
Do your policies have versions? Can employees easily identify the latest version, or do you have several versions flying around?
Are your policies reviewed regularly? How old are your policies? Might they be outdated? Ideally, there should be a review at least once a year.
Do your policies have an expiration or next review date? Is this date clearly visible within the policy?
Does each policy have an owner? Whom to ask if there are questions about a policy? Is the owner’s name listed within the policy?
Communicating Policies
Communication is key when implementing policies. Ensuring that every employee is aware of and understands each policy is essential. This involves:
Evidence of Reach: Is there proof that every employee has received the policy, perhaps through email or other communication channels?
Training: Is training provided for each policy to ensure understanding?
Feedback Channel: Is there a way to collect and address questions, suggestions, or concerns regarding a policy?
Acknowledgment System: Is there a system in place where every employee has to acknowledge or sign that they have understood the policy?
Essential Policies and Their Purpose
Core Policies:
Anti-discrimination and Harassment Policy: Prohibits discrimination and harassment based on various factors and outlines procedures for complaints.
Equal Employment Opportunity Policy: Declares the company’s commitment to equal employment opportunity in all aspects of employment.
Workplace Safety and Health Policy: Demonstrates the commitment to a safe workplace and details safety procedures.
Sustainability/Environmental Policy: Outlines commitments to sustainable practices and environmental responsibility.
Confidentiality and Information Security Policy: Protects information and outlines handling procedures.
Data Protection and Privacy Policy: Details how personal data is collected, used, stored, and protected, both for employees and customers.
Conflicts of Interest Policy: Defines and outlines procedures for disclosing and resolving conflicts of interest.
Quality Policy: States the commitment to quality products and services.
Business Continuity Plan: Outlines how operations will continue during and after a disruptive event.
Code of Conduct / Ethics Policy: Establishes expectations for employee behavior and outlines consequences for violations.
Other Recommended Policies:
Drug-free Workplace Policy: Prohibits the use of illegal drugs and alcohol in the workplace.
Social Media Policy: Outlines expectations for social media use.
Internet and Email Usage Policy: Provides guidelines for appropriate use of company internet and email.
Leave Policy: Details policies on various types of leave.
Performance Evaluation Policy: Outlines the process for evaluating employee performance.
Compensation and Benefits Policy: Details the structure of compensation and benefits.
Signing Policy: Defines authorization for signing documents on behalf of the organization.
Customer Care Policy: Sets guidelines for interacting with customers and resolving issues.
Complaints Handling Policy: Outlines how customer complaints will be received, investigated, and resolved.
By addressing the above aspects, companies can ensure that their policies are effective, well-communicated, and understood, thus fostering a harmonious and productive work environment.
Blueprint for Brilliance: Crafting Your Policy Compass – Navigating Towards Organizational Success
Now that we’ve unlocked the mysteries of policies and understood their pivotal role, it’s time to craft your own policy compass. Start by assessing your existing policies, ensuring they are accessible, well-communicated, and understood by all. Develop a robust system for policy communication, training, and acknowledgment. Don’t forget to regularly review and update your policies to navigate the ever-changing business seas successfully.
Call to Action
Embark on your journey towards organizational excellence by fortifying your company with well-established and communicated policies. Set sail towards stability and prosperity, and watch your ship navigate smoothly through the corporate storm!
Conclusion
Navigating through the storm requires a sturdy ship, a skilled crew, and a reliable compass. In the world of business, policies are your compass, guiding you toward success and stability. Embrace them, communicate them, and watch your company sail towards a horizon of endless possibilities!
Remember, a ship in the harbor is safe, but that is not what ships are built for. Set sail, navigate through the storm, and discover the treasures that await with effective policies. Safe travels, dear reader, until our next enlightening adventure!
The Allure of Consistency: Why Maintainability Matters
In today’s fast-paced world, products and services must be reliable, robust, and resilient. But more than that, they need to be sustainable. That’s where maintainability comes in. It’s the unseen force that ensures our favorite tools, platforms, and systems keep running smoothly, day in and day out.
Maintainability, at its core, measures how easily a product or system can be preserved in its functional state. It answers questions like: How quickly can we respond to unforeseen issues? How efficiently can updates be implemented? And how effectively can we avoid future problems?
Here’s why maintainability is so much more than a mere operational necessity:
Cost Efficiency: Initial development and deployment might seem like the most expensive aspects of a product, but long-term maintenance can significantly add to these costs. If a system is designed with maintainability in mind, these ongoing costs can be substantially reduced. Fewer person-hours, fewer resources, and less downtime translate directly into cost savings.
User Trust: We live in an era of instant gratification. If a system or service breaks down, users expect quick resolutions. Systems that are maintainable foster user trust because they assure users that issues will be resolved promptly and effectively. And in the digital age, trust is the currency that drives loyalty.
Flexibility & Adaptability: Markets change. Technologies evolve. A maintainable system is, by design, more adaptable to these changes. It allows for easier upgrades, smoother integrations, and quicker pivots, ensuring the system remains relevant and effective in the face of change.
Longevity: In the business world, it’s not just about creating the next big thing; it’s about ensuring that the ‘big thing’ lasts. Maintainability extends the lifespan of a product or system. When products last longer, businesses can maximize ROI and build a more substantial brand reputation.
Reduced Risk: Every moment a system is down, there’s a risk—lost revenue, unsatisfied customers, and potential data breaches. With higher maintainability, these downtimes are reduced, mitigating the associated risks.
In essence, maintainability isn’t a feature you add after the fact; it’s a philosophy you embed from the outset. It’s about foreseeing tomorrow’s challenges and designing systems today that can weather them. In the world of quality management, maintainability isn’t just a term—it’s the embodiment of foresight, adaptability, and commitment to lasting quality.
A Painful Oversight: How Ignoring Maintainability Cost Us
Every product journey has its highs and lows. While we often revel in the success stories, it’s the mistakes and oversights that teach us the most valuable lessons. Our story is one such lesson, a poignant reminder of the price we pay when we overlook the essence of maintainability.
It all started with a product we believed was a masterpiece. Months of planning, development, and testing culminated in a system we were genuinely proud of. But pride, as they say, often precedes a fall.
Not long after launch, feedback from a customer hinted at an underlying issue—a glitch that seemed minor on the surface. Optimistically, we thought it would be a quick fix. But as we dove deeper, the ramifications of our oversight became painfully clear.
Duplication Dilemma: The product’s codebase was riddled with duplications. What seemed like shortcuts during development now stood as barriers to efficient troubleshooting. This meant that an error wasn’t isolated to one part but echoed across multiple facets of the product.
The Domino Effect: Fixing the reported error was time-consuming, but that was just the tip of the iceberg. The error kept reappearing in different guises because the fix wasn’t uniformly applied due to the duplicated code. Each recurrence chipped away at our team’s morale and, more importantly, our reputation with the customer.
Customer Dissatisfaction: In today’s interconnected world, a single customer’s dissatisfaction can ripple out, affecting perceptions and trust. Our lack of maintainability didn’t just result in a recurring error; it tarnished our brand’s image. What could’ve been a minor hiccup transformed into a lingering issue that cost us not only time and resources but also customer trust.
The Reality Check: This experience was a wake-up call. It underscored the importance of designing products with maintainability as a cornerstone, not an afterthought. Short-term conveniences can lead to long-term challenges, and in our quest for quick solutions, we inadvertently compromised on the product’s foundational quality.
The silver lining? Mistakes, as painful as they might be, pave the way for growth. This episode propelled us to reevaluate our processes, placing maintainability at the forefront of our development philosophy.
Beyond Quick Fixes: The Science of Maintaining Systems
Every robust system or product isn’t just a result of innovative design but also a testament to meticulous maintainability practices. But to truly appreciate its essence, we must understand the nuances of maintainability and the tools that drive it.
Understanding Maintainability: It’s more than just a buzzword; maintainability is the art and science of ensuring a system’s long-term reliability. But how exactly do we measure and optimize it?
Preventive Maintenance: Proactivity is the hallmark of preventive maintenance. By regularly analyzing and updating systems, potential pitfalls are identified and addressed ahead of time. The aim? Reduce failures and boost system longevity.
Corrective Maintenance: No system is flawless, but how quickly and effectively it recovers from setbacks indicates its maintainability. Corrective maintenance is all about swift and efficient troubleshooting, with the Mean Time To Repair (MTTR) being a key performance indicator.
Harnessing the Power of Design: While design dictates user experience, it also profoundly impacts maintainability. Systems conceived with maintenance in mind are:
Easier to update.
Streamlined for integrations.
More straightforward to troubleshoot.
Tools of the Trade: Prevention at Its Best:
Static Code Analysis: One of the first lines of defense against maintainability issues. Tools that perform static code analysis meticulously comb through codebases without executing the program. They pinpoint problematic areas, whether it’s duplicated code or convoluted logic, that could become a headache down the line.
Code Complexity Metrics: Understanding the complexity of the code can provide insights into potential maintenance challenges. Complex code might be harder to maintain and more prone to errors. Tools that measure code complexity help developers streamline and simplify, promoting cleaner, more maintainable code.
Regular Code Reviews: Instituting regular code reviews within teams can identify potential issues before they escalate. These peer reviews ensure code quality, consistency, and maintainability.
A Delicate Dance of Availability and Maintainability: Both these aspects are pillars of a product’s quality. While availability ensures users have access when needed, maintainability guarantees the system remains reliable over time.
Reimagining Development: In the ever-evolving landscape of technology, the focus isn’t just on creating; it’s about sustaining. With the right tools and a proactive approach, maintainability takes center stage, ensuring products are innovative and enduringly reliable.
Your Action Plan: Making Maintainability A Habit
Maintainability isn’t a one-time endeavor; it’s a continuous commitment. It’s not just about creating systems that function efficiently today but crafting legacy systems that will be hailed for their reliability years down the line. Here’s a structured plan to make maintainability a habitual part of your development process.
1. Equip with the Right Tools: Invest in the essentials.
Code Analyzers: Delve into tools like SonarQube, SAST or Coverity. Their strength lies in pinpointing issues and offering actionable insights to rectify them.
Adopt CI Platforms: Embrace platforms like Jenkins or Travis CI to seamlessly integrate every new code change without disrupting existing functionalities.
2. Pledge to Pristine Code: Quality over quantity always.
Adopt refactoring as a regular practice to keep code lean and efficient.
Stick to recognized coding conventions, ensuring every line written echoes clarity.
Prioritize documentation. It’s the bridge between current developers and future maintainers.
3. Champion Continuous Learning: Maintainability evolves, and so should you.
Stay updated with the latest best practices through workshops, training sessions, or online courses.
4. Valuing Feedback as Gold: Constructive criticism is a developer’s best friend.
Encourage feedback loops from peers, users, or third-party audits. It’s the compass that points to areas ripe for improvement.
5. Map Out Maintenance: A well-planned path ensures fewer hiccups.
Craft a detailed maintenance roadmap. From regular system checks to updates, ensure every step is well-planned and executed.
The Starting Line: For those still on the fence about maintainability, let our earlier story serve as both a cautionary tale and an inspiration. Start today; integrate maintainability into every phase of your development process.
By making maintainability a regular habit, you’re ensuring seamless operations today and setting the stage for a legacy of reliability. With the roadmap above, the journey towards sustained excellence begins.
Unlocking a Core Metric: The Essence of Availability
In the vast business world, many metrics and measures help determine success. Sales figures, customer reviews, growth rates – these are all critical. However, nestled among these high-profile metrics is a quieter yet incredibly impactful measure known as “Availability.” But what exactly is it?
At its simplest, availability assures that a product, service, or system will be there when needed. It’s like expecting the sun to rise every morning or your favorite coffee shop to be open when you need that early-morning caffeine fix. Imagine a scenario where you walk up to the coffee shop, and it’s unexpectedly closed. That disappointment, that disruption to your routine – that’s what happens when availability falters in the business world. For a company, it could mean a service not being accessible, a website crashing during a peak sales hour, or a product failing when a customer needs it most.
In essence, availability isn’t merely about uptime; it’s about trust, reliability, and a business’s commitment to its customers. As we delve deeper into this topic, we’ll explore its nuances, its importance, and why businesses, big or small, should prioritize it.
The Four 9’s Epiphany: A Glimpse into High-Stakes Availability
Imagine for a moment, a bustling city that never sleeps. People in this city go to restaurants, hairdressers, theaters, bars, etc. There, they pay cash or with credit cards. Hence, there is an endless flow of payment transactions every single second, day in and day out. People would be depressed if such a transaction fails or even crashes. Imagine your credit card is declined in a restaurant, and you don’t have cash. Or even worse, you draw money from an ATM, but the system crashes before you get the money out of the machine, but your account has been charged already. Not good. Hence, you want the involved system to be available, always. What if you learned that your bank promises to run its servers or ATMs 99.9999% of the time? It’s a bold promise, almost hard to believe. That’s roughly half a minute of downtime in an entire year!
Behind this promise lies an army of dedicated professionals: engineers, technicians, and customer service staff, all working around the clock. These individuals ensure that there is a lot of redundancy for the servers, that maintenance windows are scheduled and performed without interrupting the service, that security updates are installed regularly, and that all possible scenarios are tested sufficiently. The goal isn’t just about keeping the service running; it’s about upholding a commitment to the millions who rely on it.
This payment story vividly illustrates the lengths some sectors go to ensure availability. The magic of the four 9s isn’t just in its impressive statistic; it’s in the trust it builds with every customer who uses the service, confident that the payments are booked correctly and without interruptions. And just like our payment example, the emphasis is on the importance of availability, the dedication to ensuring it, and the implications of failing to meet those standards. And luckily, usually it doesn’t need that many 9s to build up that customer confidence and trust.
The ABCs of Availability: Beyond Just Uptime
At its heart, availability is a commitment, a promise that businesses make to their stakeholders. But how do we measure such a commitment? Like most promises, some science and math are behind it. Let’s break it down using easy-to-understand analogies:
What Does Availability Really Mean? Think of availability as a shop that you like visiting. If it’s open every time you go there, it has high availability. If it’s often closed unexpectedly, its availability is lower. In technical terms, it’s the amount of time something works as expected compared to the entire time it should be.
Understanding Operational Availability: Imagine you have a toy that works for 10 hours but then needs a 1-hour break to recharge. This toy’s ‘Operational Availability’ would be the time it works without needing a break compared to the total time it’s been used. In numbers, this would be calculated as:
MTBF (Mean Time Between Failures) divided by the sum of MTBF and MDT (Mean Down Time). It measures how often something works compared to the combined time of working and being broken.
In our toy example, this would be 0,9 or 90% availability.
Diving into Intrinsic Availability: There is another type of availability used quite often. It’s called “Intrinsic Availability”. In contrast to “Operational Availability,” we consider the repair time only here. Scheduled downtimes and maintenance are not considered since the product, service, or system would be technically available. It is not broken, just not used right now to do maintenance. Hence, it is just a different way to look at availability.
In terms of a formula, this is MTBF divided by the sum of MTBF and MTTR (Mean Time To Repair).
Intrinsic Availability = MTBF / (MTBF + MTTR)
Coming back to our toy example. The charging time is not considered as repair time. Hence the Intrinsic Availability would be 100% if no repairs would be necessary at all.
There are even more types of availability, e.g., Technical Availability, Inherent Availability, or Achievable Availability. But I’ll skip those here for now.
Important would be that you know which kind of availability you want to measure and why. And, of course, how to interpret those numbers.
By understanding these terms and concepts, businesses can pinpoint where they stand regarding their commitment to stakeholders. They can see how often their systems or products might falter and how quickly they can recover when they do. In essence, availability isn’t just a buzzword; it reflects a business’s resilience and reliability.
Making Every Second Count: The Business Imperative of Availability
Availability is often under the spotlight in the vast web of business operations. This isn’t just because of its technical significance but its profound business implications. Here’s why every tick of the clock matters and how businesses can capitalize on the promise of availability:
The Cost of Downtime: Let’s picture a buzzing online store. Imagine it suddenly crashing on Black Friday. Every moment it’s down, potential sales evaporate. Beyond just immediate losses, such incidents can deter future customers. Downtime, in essence, hits the business pocket both in the present and in potential future revenues.
Building Trust through Reliability: Consider a bank ATM. If it fails to dispense cash occasionally, users become wary. The more reliable an ATM, the more people trust that bank. Regardless of their sector, businesses earn their customers’ trust by ensuring consistent availability. It signals to the customer that the company is dependable and that they can count on it.
Reputation: The Silent Stakeholder: In our interconnected digital age, news travels fast. If a service is frequently unavailable, it doesn’t take long for this information to spread, potentially damaging a company’s reputation. A solid reputation can take years to build but only moments to tarnish.
Stepping Up to the Challenge: So, how can businesses navigate these waters? Regular maintenance is a crucial first step. Many disruptions can be avoided by proactively identifying potential issues and rectifying them. Investing in robust infrastructure and technologies is another essential aspect. Such investments not only bolster availability but can also offer competitive advantages in the market. Lastly, it’s pivotal to maintain open channels of communication with customers. By understanding their needs and feedback, businesses can better align their availability goals with customer expectations.
In the grand theater of business, where various elements play their part, availability stands out as a silent guardian. It ensures smooth operations, builds trust and fortifies reputation. For companies aspiring to lead in their domains, prioritizing availability isn’t just an option; it’s an imperative.
In today’s fast-paced product world, impeccable quality is a non-negotiable aspect. Yet, what happens when an initially flawless product begins revealing its hidden defects over time? This raises a critical question about the importance of product reliability.
The Hidden Troubles of A Product
Consider a product that performed brilliantly and met every expectation right out of the box. Users were thrilled, and the product seemed destined for long-term success. But as time progressed, unforeseen issues began to surface. After several weeks, those minor glitches transformed into significant setbacks, drastically impacting user experience. The problem wasn’t the quality during production but its performance over an extended period. Such a situation underscores the pivotal importance of Reliability in product design and testing.
Unveiling Reliability
Defining Reliability
What is Reliability exactly? How to define it?
“Reliability is the ability of a product, system, or service to consistently perform its intended function over a specified period of time without failure.”
Think of Reliability as a product’s stamina. Just as a marathon runner needs the endurance to maintain performance over long distances, products must have the resilience to operate faultlessly over prolonged periods. It’s not just about shining at the start but maintaining that brilliance over the entire product lifecycle.
Measuring Reliability
But how do you measure if a product is reliable? Reliability is quantified through various metrics, primarily focusing on the product’s failure rate or the number of malfunctions per unit of time.
MTTF (Mean Time To Failure): This represents the average time a product operates before it fails. For instance, if five units of a product functioned for 10, 20, 30, 40, and 50 hours, respectively, before failing, the MTTF would be the average of these times, which is 30 hours. Of course, the longer this time period, the better.
MTBF (Mean Time Between Failures): This is relevant for products that can be repaired and reused. If a machine fails every 20 days and takes one day to repair, its MTBF is 19 days. It signifies the average operational duration between failures. Also, here, you want this number to be very high.
Elevating Product Excellence Through Reliability
So what can be done about it? To ensure Reliability in products, services, or systems, you can do the following:
Reduce Complexity:
Description: Streamlining a product’s design can significantly enhance its resilience. Minimizing unnecessary components or functionalities reduces the potential points of failure.
Example: Consider a remote control. While having multiple buttons for numerous functions may seem advantageous, it also increases the chances of a button malfunctioning. By focusing only on essential buttons and perhaps integrating multifunctionality into a few, you simplify the design and improve the remote’s Reliability.
Enhance Component Reliability:
Description: Every part of your product, be it physical or software, should be vetted and tested extensively to ensure prolonged Reliability.
Example: In manufacturing a wristwatch, if the cogwheel material is prone to wear and tear, replacing it with a more durable material—even if slightly more expensive—will result in a more reliable final product.
Incorporate Redundancy:
Description: Redundancy means having backup components or systems in place to ensure continuous functionality even if a primary system fails.
Example: In cloud storage solutions, data is often replicated across multiple servers or even locations. If one server faces an outage, the data remains accessible from another, ensuring consistent service.
Prioritize Regular Maintenance:
Description: Scheduled maintenance, both preventive (to stop failures from happening) and corrective (repairing after a failure), ensures your product remains in optimal working condition.
Example: Regularly updating software can prevent potential security breaches or system glitches. Similarly, routinely servicing a car, including oil changes and tire rotations, ensures it runs smoothly and reduces the likelihood of unexpected breakdowns.
Design Thinking for Reliability:
Description: During the product design phase, incorporate a robust review process centered on Reliability. Ensure that designs are critically analyzed for potential long-term issues.
Example: Engineers might prioritize a unibody design for aesthetic reasons when designing a smartphone. However, considering Reliability, they might opt for a design that allows easier battery replacements, prolonging the device’s lifespan and ensuring customers don’t face power issues after a couple of years of usage.
Reliability transcends mere functionality. It’s a testament to a product’s endurance, consistency, and the trust customers can place in it. By implementing these tools and approaches, products not only meet but also surpass user expectations throughout their lifecycle.
Conclusion
Reliability is the unsung hero in the world of tangible or digital products. While the initial appeal might draw users in, it’s the consistent, dependable performance over time that builds trust and fosters long-term loyalty.
Reliability is much like a bridge – it connects a product’s promise to its sustained delivery, ensuring that what’s offered today remains true tomorrow, next month, and years down the line.
Yet, achieving this Reliability isn’t a stroke of luck; it’s a calculated endeavor. By embracing simplified designs, meticulously selecting and testing components, preparing for unforeseen circumstances with redundancy, conducting regular checks and maintenance, and continually rethinking design for longevity, we set the stage for products that stand the test of time.
But remember, Reliability isn’t a one-time task; it’s a perpetual commitment. It demands attention, resources, and a mindset that prioritizes long-term gains over short-lived glories.
What next?
For all professionals dedicated to offering value – be it in design, testing, manufacturing, or any part of the product lifecycle – take a moment today to evaluate the reliability quotient of your offerings. Are they merely dazzling at first glance, or do they promise an enduring brilliance? If you haven’t considered Reliability a cornerstone yet, now’s the perfect moment to start. Let’s champion products that don’t just deliver but persistently excel. Dive deeper, think longer, and let’s build for the future!
Why Every Organization Must Prioritize Change Management
Why Change Management? In today’s digital age, the only constant is change. Organizations are continuously compelled to adapt, evolve, and innovate to keep up with market demands, technological advancements, and competitive pressures. And while change can unlock unprecedented growth opportunities, it also presents unique challenges.
A well-orchestrated Change Management Strategy ensures that an organization doesn’t just adapt to these changes but thrives amidst them. Successful change management isn’t just about introducing a new system or process; it’s about transforming the organizational culture, aligning teams with a shared vision, and ensuring that changes are sustainable in the long run.
When Good Intentions Go Wrong
My Personal Encounter with Failed Change.
I still recall the optimism surrounding introducing our new product development process. Charts showcased enhanced efficiencies, and management was excited about heightened transparency.
But the implementation told a different story. The new framework drastically changed how teams operated. The daily tasks that were once autonomous were now meticulously documented, leaving many feeling micromanaged. Despite initial training sessions and the promise of better results, morale declined. Bypasses were discovered, loopholes exploited, and the very system that was to be our salvation became a daily challenge. The lesson? Change is more about people than processes.
Anatomy of Successful Change Management: Building a Strategy that Stands the Test of Time
The following 4 phases provide a framework for successful change management.
Phase 1: Laying the Groundwork – Assessing Change Readiness
Before any significant change, assessing an organization’s readiness is essential. By answering a set of strategic questions, you can identify potential enthusiasm blockers, areas of resistance, and teams or departments that might struggle more than others. This proactive assessment can be the difference between smooth adaptation and turbulent upheaval.
Phase 2: Igniting Passion – Cultivating Enthusiasm for Change
Successful change is driven by the collective effort of an organization’s individuals. Organize feedback sessions, workshops, and town halls to address concerns, showcase benefits, and present the vision behind the change. Making teams a part of the change journey, rather than just recipients, fosters ownership and commitment.
Phase 3: From Hesitation to Dedication – Ensuring Employee Commitment
Clear, consistent communication is essential. Regularly update teams about the change progress, celebrate small victories, and provide platforms for questions and concerns. Individual conversations, where team members can express their hesitations and seek clarity, further help bridge gaps and ensure everyone is on board.
Phase 4: Sustainability – Embedding Change through New Habits
While initial acceptance is crucial, ensuring the change sticks is the real challenge. Post-implementation reviews, ongoing training sessions, and feedback mechanisms help identify areas of improvement and ensure that the new practices become second nature.
The Road Ahead: Crafting Your Unique Change Management Strategy
Every organization’s change journey is unique, influenced by its culture, history, and objectives. The Change Curve—ranging from the status quo to eventual evolution—captures the emotional journey of individuals and teams during transformation. Recognizing and addressing these emotions, from resistance to resignation, is pivotal in ensuring successful change.
As daunting as change may seem, equipped with the right strategy, tools, and mindset, it’s an opportunity to redefine, reimagine, and rejuvenate. Embrace change not as a challenge but as a catalyst, propelling your organization into its next growth chapter.
Note: There is also a whitepaper available in our Whitepaper-Download-Section, elaborating on the topic in more detail.
Waste is often overlooked in many business processes, yet it can profoundly impact efficiency, cost, and overall productivity. The concept of the “7 mudas,” originating from Lean Manufacturing principles, helps companies identify and eliminate different forms of waste, promoting a streamlined and efficient operation. Let’s dive into the world of the “7 mudas” and understand how you can implement these principles in your business.
Origin of the 7 Mudas
The “7 mudas” concept comes from the Toyota Production System (TPS), developed by Taiichi Ohno. “Muda” is a Japanese term that means wastefulness or futility. In the context of Lean Manufacturing, it refers to anything that doesn’t add value to the product or service. By identifying and eliminating these seven forms of waste, companies can increase efficiency and reduce costs.
The 7 Mudas Explained with Examples
Transportation: This refers to the unnecessary movement of materials, parts, or finished products between processes or locations.
Example: Transferring products between multiple warehouses or facilities without adding value leads to higher transportation costs and possible damage.
Solution: Mapping and optimizing transportation routes, consolidating shipping, and synchronizing supply chain partners can drastically reduce this waste.
Inventory: Keeping excess inventory, whether in raw materials, work-in-progress, or finished goods, ties up capital and can lead to obsolescence.
Example: Stockpiling raw materials without aligning them to actual production schedules may result in spoilage or obsolescence.
Solution: Implementing a Just-In-Time (JIT) inventory management system ensures materials arrive as they are needed, thus reducing carrying costs and risks.
Motion: Unnecessary movement of people or equipment within a process that doesn’t add value and often leads to ergonomic issues.
Example: Employees spending time reaching for tools or walking to distant parts of a facility or far away meeting rooms.
Solution: Using ergonomic studies and workflow analysis to redesign workspaces can reduce unnecessary movements, improving efficiency and worker safety.
Waiting: This waste occurs when resources are idle, waiting for something to happen, like a machine waiting for parts or someone waiting for information.
Example: An assembly line waiting for parts to arrive due to a misaligned schedule or a team waiting for a software component from another group.
Solution: A synchronized production schedule and real-time tracking can prevent delays and keep processes running smoothly. Solid dependency management will reduce waiting times in addition.
Overproduction: Producing more items than what’s immediately needed, leading to excess inventory and potential loss.
Example: Manufacturing 1000 widgets for an anticipated order of 800, resulting in excess storage costs and potential markdowns.
Solution: Embracing a demand-driven production model that aligns closely with real-time customer needs ensures resources are not wasted on unneeded products.
Overprocessing: Doing more work, using more components, or utilizing more complex processes than required to meet customer needs.
Example: Using a high-precision machine to drill a hole that doesn’t require such precision, consuming more energy and time.
Solution: Analyzing customer requirements closely and matching the production or development process to those specific needs avoids overcomplicating tasks and saves resources.
Defects: Any imperfection or error in a product or service that requires correction, leading to rework, returns, and dissatisfaction.
Example: A batch of electronic devices shipped with faulty batteries, leading to customer complaints, returns, and the cost of replacements.
Solution: Implementing rigorous quality checks, using error-proofing techniques, and fostering a quality culture can minimize defects and related costs.
Conclusion
Understanding and addressing the “7 mudas” is more than a manufacturing technique; it’s a mindset that can transform your business, independent from the type of your business (e.g. Software development). By eliminating these wastes, you position your company to be more competitive, agile, and customer-focused.
Start by assessing your current processes to identify areas where these forms of waste might occur. Collaborate with your team, encourage innovation, and create a culture where continuous improvement is embraced.
Take the leap today and join the movement toward a more efficient, productive, and waste-free operation. Your business—and your bottom line—will thank you.
In the world of software development, testing plays a crucial role in ensuring the quality and reliability of the final product. “Static Testing” is a fundamental, but still heavily underestimated, test design technique among various testing approaches. This blog post aims to shed light on what static testing entails, its significance in the development process, and its multiple sub-types.
What is Static Testing?
Static testing is a software testing technique that evaluates the software without executing the code. Unlike dynamic testing, where the application is run to identify defects, static testing examines the software artifacts such as requirements, design documents, source code, and test cases to detect errors early in the development life cycle. This proactive approach helps reduce the number of defects introduced into the system, leading to cost and time savings.
Test Design Techniques – Static Testing vs. Dynamic Testing
Static and dynamic testing are two primary test design techniques employed during software development. While static testing is non-execution-based and focuses on detecting defects at an early stage, dynamic testing, on the other hand, involves running the software to observe its behavior and identify issues during runtime.
There are different approaches and aspects when it comes to static testing.
Informal Reviews
Informal reviews are simple, ad-hoc discussions and inspections performed by developers or team members. This collaborative approach involves team members casually examining software artifacts, such as requirements, design documents, or test cases, to detect defects and improve overall quality. Informal reviews are lightweight and flexible, encouraging open communication among team members. While they may not catch all complex issues, they serve as an excellent starting point for early defect detection and fostering knowledge sharing within the team.
Walk-throughs
Walk-throughs are more structured than informal reviews, involving step-by-step examinations of documents, code, or test cases. A designated moderator leads the discussion during a walk-through while the author presents the artifact. The participants actively engage by providing feedback, asking questions, and suggesting improvements. This collaborative process aims to enhance the software artifacts’ clarity, accuracy, and completeness. Walk-throughs are valuable for detecting ambiguities, inconsistencies, and logical flaws early, ensuring a better understanding of the software under development.
Technical Reviews
Technical reviews are formal evaluations conducted by technical experts, often from outside the development team. These experts have expertise in the relevant domain and can objectively assess the software artifacts. Technical reviews delve deep into the technical aspects of the software, scrutinizing the source code, design documents, and architecture for adherence to coding standards, best practices, and industry guidelines. By involving external experts, technical reviews can uncover potential blind spots and bring fresh insights to the development process, resulting in higher-quality software.
Inspections
Inspections are highly structured and rigorous evaluations involving multiple stakeholders, including developers, testers, and managers. The inspection process follows a predefined set of rules and guidelines, focusing on comprehensive defect detection. Each participant has a specific role during the inspection, such as a reader, recorder, or moderator. The inspection team carefully examines the software artifacts, and all identified defects are logged for later resolution. The formal and systematic nature of inspections ensures a high level of software quality and reduces the chances of defects escaping to later phases of development.
Static Analysis
The static analysis utilizes automated tools to examine the source code or other software artifacts without executing them. This technique aims to identify potential defects, vulnerabilities, and adherence to coding standards.
There are plenty of tools for static code analysis. One more prominent example would be SonarQube.
SonarQube is a popular open-source platform that supports various programming languages like Java, C#, JavaScript, Python, and more. It provides a comprehensive set of rules to analyze code quality, security, and maintainability. SonarQube offers detailed reports and dashboards to monitor code quality over time.
But this is just one example, and there are many more, specialized in different programming languages or with a particular focus.
The static analysis offers two main sub-types:
Data Flow Analysis
Data flow analysis examines the flow of data within the software, tracking the path of variables and values as they traverse through the program. This analysis helps detect issues like uninitialized variables, data leaks, or data corruption. By understanding how data moves through the code, developers can pinpoint potential weaknesses and enhance the security and robustness of the application.
Control Flow Analysis
Control flow analysis focuses on analyzing the flow of control and decision-making in the software. This analysis identifies problems related to loops, conditional statements, and unreachable code. By visualizing the program’s execution paths, developers can identify logic errors, dead code, and potential vulnerabilities, leading to more efficient and reliable software.
Conclusion
By understanding and employing various sub-types of static testing, software development teams can proactively identify defects, enhance collaboration, and improve the overall quality of their products. From informal reviews to advanced static analysis techniques, each approach contributes to creating dependable, secure, and high-performing software applications. Incorporating static testing as an integral part of the development process helps build a strong foundation for successful software delivery and customer satisfaction.
Exploring the World of Test Design Techniques: Improving Software Quality One Step at a Time
Software testing is crucial in ensuring any application’s quality and reliability. Among the many facets of testing, test design techniques form the backbone of a well-structured testing process. In this blog post, we will delve into the various test design techniques, their definitions, and how they contribute to the overall success of software testing.
So what are Test Design Techniques?
Test Design Techniques encompass a variety of methods and approaches used by testers to create effective and efficient test cases. These techniques help ensure that test coverage is comprehensive, defects are identified, and the software meets the specified requirements. It is basically about methods, designing or selecting the right test cases to obtain the best coverage and, ultimately, the optimal test strategy.
There are two primary categories when it comes to Test Design Techniques:
Static Testing
Dynamic Testing
The short version is: static test design techniques are applied before the software code is executed and focus on examining and verifying software artifacts. In contrast, dynamic test design techniques are used during the execution of the software code to validate its behavior and identify defects. Both techniques complement each other and are essential for a comprehensive and effective software testing process.
Now let’s look deeper into those two categories since there are a couple of sub-categories.
Test Design Techniques – Static Testing
Static test design techniques are applied without executing the software code. They analyze software artifacts, such as requirements, design documents, and code, to identify defects and ensure quality. These techniques are typically employed early in the software development life cycle and help prevent defects from propagating to later stages, reducing the cost of fixing them.
Examples are:
Informal Reviews
Informal reviews involve team members casually examining the documentation and code to identify potential defects and improvements. It is a lightweight and collaborative way to detect issues early in development.
Walk-throughs
Walk-throughs are interactive meetings where the development team presents the software artifacts to stakeholders for feedback and review. This technique facilitates a thorough system understanding, leading to valuable insights and improvements.
Technical Reviews
Technical reviews focus on evaluating the technical aspects of the software, such as architecture, design, and code. This technique helps identify technical risks and ensures compliance with coding standards.
Inspections
Inspections involve a formal and disciplined review process, focusing on finding defects in the software documentation and code. It ensures high-quality deliverables and reduces the number of defects in the later stages.
Static Analysis
That’s another form of static testing also examining software artifacts, such as source code and documentation. It aims to identify potential defects and improve code quality by analyzing the structure, syntax, and adherence to coding standards.
There are two sub-types:
Data Flow: Data flow analysis identifies how data moves through the software, helping to uncover potential data-related issues.
Control Flow: Control flow analysis examines the order in which various program statements are executed, aiding in detecting logic-related problems.
Test Design Techniques – Dynamic Testing
On the other hand, dynamic test design techniques are applied by executing the software code and observing its behavior during runtime. These techniques focus on validating the software against specific test cases and scenarios, checking for defects, and ensuring that it meets the functional and non-functional requirements.
Black-Box Testing (aka Specification-based)
Equivalence Partitioning: This technique divides the input domain into data classes, making choosing representative test cases from each class efficient, thereby maximizing test coverage.
Boundary Value Analysis (BVA): BVA focuses on test cases at the edges of equivalence partitions, where defects are more likely to occur due to boundary-related issues.
Decision Tables: Decision tables are used to represent complex business rules, making it easier to identify different combinations of conditions and corresponding actions.
Use Case Testing: Use case testing aligns test cases with user scenarios, ensuring that the software functions correctly from an end-user perspective.
State Transition: This technique is used for systems with distinct states, helping to effectively test the transition between states.
White-Box Testing (aka Structure-based)
Statement Testing: Statement testing aims to execute every statement in the code at least once, ensuring basic functionality is operational.
Decision Testing: Decision testing ensures that all possible decisions in the code are evaluated, increasing the likelihood of catching logic errors.
Condition Testing: Condition testing evaluates all possible conditions and combinations to verify the software’s robustness against various scenarios.
Experience-based testing is a testing approach that relies on the knowledge, skills, and expertise of individual testers to design, execute, and evaluate test cases. Unlike formal test design techniques that follow predefined processes, experience-based testing allows testers to leverage their intuition and past experiences to discover defects and assess the overall quality of the software.
Exploratory Testing: In exploratory testing, testers rely on their skills, knowledge, and creativity to discover defects and assess overall software quality.
Error Guessing: Error guessing relies on testers’ intuition and experience to anticipate potential defects and design test cases targeting those areas.
Conclusion
In conclusion, test design techniques are pivotal in optimizing the software testing process. By employing a combination of static and dynamic testing techniques, testing teams can effectively identify defects, improve software quality, and ensure that the software meets user expectations. Whether it’s the formal rigor of inspections or the creative freedom of exploratory testing, each technique contributes to building robust and reliable software applications. A well-thought-out test design strategy is an essential ingredient in the recipe for successful software development and deployment.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.